Capítulo 5 APRENDIZAJE SUPERVISADO

5.1 Datos y tipos de modelos:
En este curso se realizarán ejemplos tanto de regresión como de clasificación. Cada uno de los modelos a estudiar se implementarán tanto para respuestas continuas como variables categóricas
5.1.1 Regresión: Preparación de datos
En esta sección, prepararemos datos para ajustar modelos de regresión y de clasificación, usando la paquetería recipes. Primero ajustaremos la receta, después obtendremos la receta actualizada con las estimaciones y al final el conjunto de datos listo para el modelo.
5.1.1.1 Datos de regresión: Ames Housing Data
Los datos que usaremos son los de Ames Housing Data, el conjunto de datos contiene información de la Ames Assessor’s Office utilizada para calcular valuaciones para propiedades residenciales individuales vendidas en Ames, IA, de 2006 a 2010.
Podemos encontrar más información en el siguiente link Ames Housing Data.
library(tidymodels)
library(stringr)
library(tidyverse)
data(ames)
names(ames)## [1] "MS_SubClass" "MS_Zoning" "Lot_Frontage"
## [4] "Lot_Area" "Street" "Alley"
## [7] "Lot_Shape" "Land_Contour" "Utilities"
## [10] "Lot_Config" "Land_Slope" "Neighborhood"
## [13] "Condition_1" "Condition_2" "Bldg_Type"
## [16] "House_Style" "Overall_Cond" "Year_Built"
## [19] "Year_Remod_Add" "Roof_Style" "Roof_Matl"
## [22] "Exterior_1st" "Exterior_2nd" "Mas_Vnr_Type"
## [25] "Mas_Vnr_Area" "Exter_Cond" "Foundation"
## [28] "Bsmt_Cond" "Bsmt_Exposure" "BsmtFin_Type_1"
## [31] "BsmtFin_SF_1" "BsmtFin_Type_2" "BsmtFin_SF_2"
## [34] "Bsmt_Unf_SF" "Total_Bsmt_SF" "Heating"
## [37] "Heating_QC" "Central_Air" "Electrical"
## [40] "First_Flr_SF" "Second_Flr_SF" "Gr_Liv_Area"
## [43] "Bsmt_Full_Bath" "Bsmt_Half_Bath" "Full_Bath"
## [46] "Half_Bath" "Bedroom_AbvGr" "Kitchen_AbvGr"
## [49] "TotRms_AbvGrd" "Functional" "Fireplaces"
## [52] "Garage_Type" "Garage_Finish" "Garage_Cars"
## [55] "Garage_Area" "Garage_Cond" "Paved_Drive"
## [58] "Wood_Deck_SF" "Open_Porch_SF" "Enclosed_Porch"
## [61] "Three_season_porch" "Screen_Porch" "Pool_Area"
## [64] "Pool_QC" "Fence" "Misc_Feature"
## [67] "Misc_Val" "Mo_Sold" "Year_Sold"
## [70] "Sale_Type" "Sale_Condition" "Sale_Price"
## [73] "Longitude" "Latitude"5.1.1.2 Separación de los datos
El primer paso para crear un modelo de regresión es dividir nuestros datos originales en un conjunto de entrenamiento y prueba.
No hay que olvidar usar siempre una semilla con la función set.seed() para que sus resultados sean reproducibles.
Primero usaremos la función initial_split() de rsample para dividir los datos ames en conjuntos de entrenamiento y prueba. Usamos el parámetro prop para indicar la proporción de los conjuntos train y test.
set.seed(4595)
ames_split <- initial_split(ames, prop = 0.75)El objeto ames_split es un objeto rsplit y solo contiene la información de partición, para obtener los conjuntos de datos resultantes, aplicamos dos funciones adicionales, training y testing.
ames_train <- training(ames_split)
ames_test <- testing(ames_split)Estos objetos son data frames con las mismas columnas que los datos originales, pero solo las filas apropiadas para cada conjunto.
También existe la función vfold_cv que se usa para crear v particiones del conjunto de entrenamiento.
set.seed(2453)
ames_folds<- vfold_cv(ames_train)Ya con los conjuntos de entrenamiento y prueba definidos, iniciaremos con feature engeeniring sobre el conjunto de entrenamiento.
5.1.1.3 Definición de la receta
Ahora usaremos la función vista en la sección anterior, recipe(), para definir los pasos de preprocesamiento antes de usar los datos para modelado.
Usamos la función step_mutate() para generar nuevas variables dentro de la receta.
La función step_interact() nos ayuda a crear nuevas variables que son interacciones entre las variables especificadas.
Con la función step_ratio() creamos proporciones con las variables especificadas.
forcats::fct_collapse() se usa para recategorizar variables, colapsando categorías de la variable.
step_relevel nos ayuda a asignar la categoria deseada de una variable como referencia.
step_normalize() es de gran utilidad ya que sirve para normalizar las variables que se le indiquen.
step_dummy() Nos ayuda a crear variables One Hot Encoding.
Por último usamos la función step_rm() para eliminar variables que no son de utilidad para el modelo.
Ahora crearemos algunas variables auxiliares que podrían ser de utilidad para el ajuste de un modelo de regresión, entre ella: Log(Sale_Price), la cual será la variable a predecir. Una vez que el modelo haga la predicción del logaritmo del precio, es importante calcular con la función exponencial el precio real.
receta_casas <- recipe(Sale_Price ~ . , data = ames_train) %>%
step_log(Sale_Price, skip = T) %>%
step_unknown(Alley) %>%
step_rename(Year_Remod = Year_Remod_Add) %>%
step_rename(ThirdSsn_Porch = Three_season_porch) %>%
step_ratio(Bedroom_AbvGr, denom = denom_vars(Gr_Liv_Area)) %>%
step_mutate(
Age_House = Year_Sold - Year_Remod,
TotalSF = Gr_Liv_Area + Total_Bsmt_SF,
AvgRoomSF = Gr_Liv_Area / TotRms_AbvGrd,
Pool = if_else(Pool_Area > 0, 1, 0),
Exter_Cond = forcats::fct_collapse(Exter_Cond, Good = c("Typical", "Good", "Excellent"))) %>%
step_relevel(Exter_Cond, ref_level = "Good") %>%
step_normalize(all_predictors(), -all_nominal()) %>%
step_dummy(all_nominal()) %>%
step_interact(~ Second_Flr_SF:First_Flr_SF) %>%
step_interact(~ matches("Bsmt_Cond"):TotRms_AbvGrd) %>%
step_rm(
First_Flr_SF, Second_Flr_SF, Year_Remod,
Bsmt_Full_Bath, Bsmt_Half_Bath,
Kitchen_AbvGr, BsmtFin_Type_1_Unf,
Total_Bsmt_SF, Kitchen_AbvGr, Pool_Area,
Gr_Liv_Area, Sale_Type_Oth, Sale_Type_VWD
) %>%
prep()Recordemos que la función recipe() solo son los pasos a seguir, necesitamos usar la función prep() que nos devuelve una receta actualizada con las estimaciones y la función juice() que nos devuelve la matriz de diseño.
casa_juiced <- juice(receta_casas)
casa_juiced## # A tibble: 2,197 × 275
## Lot_Frontage Lot_Area Year_Built Mas_Vnr_Area BsmtFin_SF_1 BsmtFin_SF_2
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 0.214 0.604 0.848 -0.572 -0.512 -0.293
## 2 0.363 -0.216 -0.114 -0.572 -0.512 -0.293
## 3 1.05 -0.0159 1.08 -0.572 1.26 -0.293
## 4 -0.173 4.87 1.15 3.49 -0.512 -0.293
## 5 0.512 0.256 1.11 0.526 1.26 -0.293
## 6 -0.233 -0.696 -0.844 -0.572 1.26 -0.293
## 7 0.125 -0.261 -0.446 -0.572 -0.512 -0.293
## 8 0.571 -0.193 -0.479 -0.572 0.819 -0.293
## 9 0.274 0.704 0.981 -0.572 1.26 -0.293
## 10 0.0651 -0.356 -0.712 -0.572 0.375 -0.293
## # … with 2,187 more rows, and 269 more variables: Bsmt_Unf_SF <dbl>,
## # Full_Bath <dbl>, Half_Bath <dbl>, Bedroom_AbvGr <dbl>, TotRms_AbvGrd <dbl>,
## # Fireplaces <dbl>, Garage_Cars <dbl>, Garage_Area <dbl>, Wood_Deck_SF <dbl>,
## # Open_Porch_SF <dbl>, Enclosed_Porch <dbl>, ThirdSsn_Porch <dbl>,
## # Screen_Porch <dbl>, Misc_Val <dbl>, Mo_Sold <dbl>, Year_Sold <dbl>,
## # Longitude <dbl>, Latitude <dbl>, Sale_Price <dbl>,
## # Bedroom_AbvGr_o_Gr_Liv_Area <dbl>, Age_House <dbl>, TotalSF <dbl>, …casa_test_bake <- bake(receta_casas, new_data = ames_test)
glimpse(casa_test_bake)## Rows: 733
## Columns: 275
## $ Lot_Frontage <dbl> 0.6607556, -1.72…
## $ Lot_Area <dbl> 0.15995167, -0.2…
## $ Year_Built <dbl> -0.34660802, 0.6…
## $ Mas_Vnr_Area <dbl> -0.5721904, -0.5…
## $ BsmtFin_SF_1 <dbl> 0.81885215, -1.3…
## $ BsmtFin_SF_2 <dbl> 0.5851851, -0.29…
## $ Bsmt_Unf_SF <dbl> -0.65580176, -0.…
## $ Full_Bath <dbl> -1.0284858, 0.79…
## $ Half_Bath <dbl> -0.7465678, -0.7…
## $ Bedroom_AbvGr <dbl> -1.0749072, 0.15…
## $ TotRms_AbvGrd <dbl> -0.9221672, -0.2…
## $ Fireplaces <dbl> -0.9297733, -0.9…
## $ Garage_Cars <dbl> -1.0124349, 0.29…
## $ Garage_Area <dbl> 1.19047388, -0.2…
## $ Wood_Deck_SF <dbl> 0.3353735, 3.013…
## $ Open_Porch_SF <dbl> -0.70298891, -0.…
## $ Enclosed_Porch <dbl> -0.3536614, -0.3…
## $ ThirdSsn_Porch <dbl> -0.1029207, -0.1…
## $ Screen_Porch <dbl> 1.9128593, -0.28…
## $ Misc_Val <dbl> -0.09569659, 0.6…
## $ Mo_Sold <dbl> -0.09320608, -1.…
## $ Year_Sold <dbl> 1.672416, 1.6724…
## $ Longitude <dbl> 0.90531385, 0.27…
## $ Latitude <dbl> 1.00647452, 1.24…
## $ Sale_Price <int> 105000, 185000, …
## $ Bedroom_AbvGr_o_Gr_Liv_Area <dbl> 0.34141287, 0.83…
## $ Age_House <dbl> 1.21786294, -0.9…
## $ TotalSF <dbl> -0.94110413, -0.…
## $ AvgRoomSF <dbl> -1.11699593, -0.…
## $ Pool <dbl> -0.0709206, -0.0…
## $ MS_SubClass_One_Story_1945_and_Older <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_One_Story_with_Finished_Attic_All_Ages <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_One_and_Half_Story_Unfinished_All_Ages <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_One_and_Half_Story_Finished_All_Ages <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_Two_Story_1946_and_Newer <dbl> 0, 0, 1, 0, 0, 1…
## $ MS_SubClass_Two_Story_1945_and_Older <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_Two_and_Half_Story_All_Ages <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_Split_or_Multilevel <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_Split_Foyer <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_Duplex_All_Styles_and_Ages <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_One_Story_PUD_1946_and_Newer <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_One_and_Half_Story_PUD_All_Ages <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_Two_Story_PUD_1946_and_Newer <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_PUD_Multilevel_Split_Level_Foyer <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_SubClass_Two_Family_conversion_All_Styles_and_Ages <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_Zoning_Residential_High_Density <dbl> 1, 0, 0, 0, 0, 0…
## $ MS_Zoning_Residential_Low_Density <dbl> 0, 1, 1, 1, 1, 0…
## $ MS_Zoning_Residential_Medium_Density <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_Zoning_A_agr <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_Zoning_C_all <dbl> 0, 0, 0, 0, 0, 0…
## $ MS_Zoning_I_all <dbl> 0, 0, 0, 0, 0, 0…
## $ Street_Pave <dbl> 1, 1, 1, 1, 1, 1…
## $ Alley_No_Alley_Access <dbl> 1, 1, 1, 1, 1, 1…
## $ Alley_Paved <dbl> 0, 0, 0, 0, 0, 0…
## $ Alley_unknown <dbl> 0, 0, 0, 0, 0, 0…
## $ Lot_Shape_Slightly_Irregular <dbl> 0, 1, 1, 0, 0, 0…
## $ Lot_Shape_Moderately_Irregular <dbl> 0, 0, 0, 0, 0, 0…
## $ Lot_Shape_Irregular <dbl> 0, 0, 0, 0, 0, 0…
## $ Land_Contour_HLS <dbl> 0, 0, 0, 0, 0, 0…
## $ Land_Contour_Low <dbl> 0, 0, 0, 0, 0, 0…
## $ Land_Contour_Lvl <dbl> 1, 1, 1, 1, 1, 1…
## $ Utilities_NoSeWa <dbl> 0, 0, 0, 0, 0, 0…
## $ Utilities_NoSewr <dbl> 0, 0, 0, 0, 0, 0…
## $ Lot_Config_CulDSac <dbl> 0, 0, 0, 0, 0, 0…
## $ Lot_Config_FR2 <dbl> 0, 0, 0, 0, 0, 0…
## $ Lot_Config_FR3 <dbl> 0, 0, 0, 0, 0, 0…
## $ Lot_Config_Inside <dbl> 1, 1, 1, 0, 1, 1…
## $ Land_Slope_Mod <dbl> 0, 0, 0, 0, 0, 0…
## $ Land_Slope_Sev <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_College_Creek <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Old_Town <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Edwards <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Somerset <dbl> 0, 0, 0, 0, 0, 1…
## $ Neighborhood_Northridge_Heights <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Gilbert <dbl> 0, 1, 1, 1, 0, 0…
## $ Neighborhood_Sawyer <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Northwest_Ames <dbl> 0, 0, 0, 0, 1, 0…
## $ Neighborhood_Sawyer_West <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Mitchell <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Brookside <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Crawford <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Iowa_DOT_and_Rail_Road <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Timberland <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Northridge <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Stone_Brook <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_South_and_West_of_Iowa_State_University <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Clear_Creek <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Meadow_Village <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Briardale <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Bloomington_Heights <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Veenker <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Northpark_Villa <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Blueste <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Greens <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Green_Hills <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Landmark <dbl> 0, 0, 0, 0, 0, 0…
## $ Neighborhood_Hayden_Lake <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_1_Feedr <dbl> 1, 0, 0, 0, 0, 0…
## $ Condition_1_Norm <dbl> 0, 1, 1, 1, 1, 1…
## $ Condition_1_PosA <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_1_PosN <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_1_RRAe <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_1_RRAn <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_1_RRNe <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_1_RRNn <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_2_Feedr <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_2_Norm <dbl> 1, 1, 1, 1, 1, 1…
## $ Condition_2_PosA <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_2_PosN <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_2_RRAe <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_2_RRAn <dbl> 0, 0, 0, 0, 0, 0…
## $ Condition_2_RRNn <dbl> 0, 0, 0, 0, 0, 0…
## $ Bldg_Type_TwoFmCon <dbl> 0, 0, 0, 0, 0, 0…
## $ Bldg_Type_Duplex <dbl> 0, 0, 0, 0, 0, 0…
## $ Bldg_Type_Twnhs <dbl> 0, 0, 0, 0, 0, 0…
## $ Bldg_Type_TwnhsE <dbl> 0, 0, 0, 0, 0, 0…
## $ House_Style_One_and_Half_Unf <dbl> 0, 0, 0, 0, 0, 0…
## $ House_Style_One_Story <dbl> 1, 1, 0, 1, 1, 0…
## $ House_Style_SFoyer <dbl> 0, 0, 0, 0, 0, 0…
## $ House_Style_SLvl <dbl> 0, 0, 0, 0, 0, 0…
## $ House_Style_Two_and_Half_Fin <dbl> 0, 0, 0, 0, 0, 0…
## $ House_Style_Two_and_Half_Unf <dbl> 0, 0, 0, 0, 0, 0…
## $ House_Style_Two_Story <dbl> 0, 0, 1, 0, 0, 1…
## $ Overall_Cond_Poor <dbl> 0, 0, 0, 0, 0, 0…
## $ Overall_Cond_Fair <dbl> 0, 0, 0, 0, 0, 0…
## $ Overall_Cond_Below_Average <dbl> 0, 0, 0, 0, 0, 0…
## $ Overall_Cond_Average <dbl> 0, 0, 1, 1, 0, 1…
## $ Overall_Cond_Above_Average <dbl> 1, 0, 0, 0, 1, 0…
## $ Overall_Cond_Good <dbl> 0, 1, 0, 0, 0, 0…
## $ Overall_Cond_Very_Good <dbl> 0, 0, 0, 0, 0, 0…
## $ Overall_Cond_Excellent <dbl> 0, 0, 0, 0, 0, 0…
## $ Overall_Cond_Very_Excellent <dbl> 0, 0, 0, 0, 0, 0…
## $ Roof_Style_Gable <dbl> 1, 1, 1, 1, 1, 1…
## $ Roof_Style_Gambrel <dbl> 0, 0, 0, 0, 0, 0…
## $ Roof_Style_Hip <dbl> 0, 0, 0, 0, 0, 0…
## $ Roof_Style_Mansard <dbl> 0, 0, 0, 0, 0, 0…
## $ Roof_Style_Shed <dbl> 0, 0, 0, 0, 0, 0…
## $ Roof_Matl_CompShg <dbl> 1, 1, 1, 1, 1, 1…
## $ Roof_Matl_Membran <dbl> 0, 0, 0, 0, 0, 0…
## $ Roof_Matl_Metal <dbl> 0, 0, 0, 0, 0, 0…
## $ Roof_Matl_Roll <dbl> 0, 0, 0, 0, 0, 0…
## $ Roof_Matl_Tar.Grv <dbl> 0, 0, 0, 0, 0, 0…
## $ Roof_Matl_WdShake <dbl> 0, 0, 0, 0, 0, 0…
## $ Roof_Matl_WdShngl <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_AsphShn <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_BrkComm <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_BrkFace <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_CBlock <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_CemntBd <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_HdBoard <dbl> 0, 1, 0, 0, 0, 0…
## $ Exterior_1st_ImStucc <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_MetalSd <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_Plywood <dbl> 0, 0, 0, 0, 1, 0…
## $ Exterior_1st_PreCast <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_Stone <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_Stucco <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_VinylSd <dbl> 1, 0, 1, 1, 0, 1…
## $ Exterior_1st_Wd.Sdng <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_1st_WdShing <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_AsphShn <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_Brk.Cmn <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_BrkFace <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_CBlock <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_CmentBd <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_HdBoard <dbl> 0, 1, 0, 0, 0, 0…
## $ Exterior_2nd_ImStucc <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_MetalSd <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_Other <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_Plywood <dbl> 0, 0, 0, 0, 1, 0…
## $ Exterior_2nd_PreCast <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_Stone <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_Stucco <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_VinylSd <dbl> 1, 0, 1, 1, 0, 1…
## $ Exterior_2nd_Wd.Sdng <dbl> 0, 0, 0, 0, 0, 0…
## $ Exterior_2nd_Wd.Shng <dbl> 0, 0, 0, 0, 0, 0…
## $ Mas_Vnr_Type_BrkFace <dbl> 0, 0, 0, 0, 0, 0…
## $ Mas_Vnr_Type_CBlock <dbl> 0, 0, 0, 0, 0, 0…
## $ Mas_Vnr_Type_None <dbl> 1, 1, 1, 1, 0, 1…
## $ Mas_Vnr_Type_Stone <dbl> 0, 0, 0, 0, 1, 0…
## $ Exter_Cond_Fair <dbl> 0, 0, 0, 0, 0, 0…
## $ Exter_Cond_Poor <dbl> 0, 0, 0, 0, 0, 0…
## $ Foundation_CBlock <dbl> 1, 0, 0, 1, 1, 0…
## $ Foundation_PConc <dbl> 0, 1, 1, 0, 0, 1…
## $ Foundation_Slab <dbl> 0, 0, 0, 0, 0, 0…
## $ Foundation_Stone <dbl> 0, 0, 0, 0, 0, 0…
## $ Foundation_Wood <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Cond_Fair <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Cond_Good <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Cond_No_Basement <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Cond_Poor <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Cond_Typical <dbl> 1, 1, 1, 1, 1, 1…
## $ Bsmt_Exposure_Gd <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Exposure_Mn <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Exposure_No <dbl> 1, 1, 1, 1, 1, 1…
## $ Bsmt_Exposure_No_Basement <dbl> 0, 0, 0, 0, 0, 0…
## $ BsmtFin_Type_1_BLQ <dbl> 0, 0, 0, 0, 0, 0…
## $ BsmtFin_Type_1_GLQ <dbl> 0, 0, 0, 0, 0, 1…
## $ BsmtFin_Type_1_LwQ <dbl> 0, 0, 0, 1, 0, 0…
## $ BsmtFin_Type_1_No_Basement <dbl> 0, 0, 0, 0, 0, 0…
## $ BsmtFin_Type_1_Rec <dbl> 1, 0, 0, 0, 0, 0…
## $ BsmtFin_Type_2_BLQ <dbl> 0, 0, 0, 0, 0, 0…
## $ BsmtFin_Type_2_GLQ <dbl> 0, 0, 0, 0, 0, 0…
## $ BsmtFin_Type_2_LwQ <dbl> 1, 0, 0, 0, 0, 0…
## $ BsmtFin_Type_2_No_Basement <dbl> 0, 0, 0, 0, 0, 0…
## $ BsmtFin_Type_2_Rec <dbl> 0, 0, 0, 0, 1, 0…
## $ BsmtFin_Type_2_Unf <dbl> 0, 1, 1, 1, 0, 1…
## $ Heating_GasA <dbl> 1, 1, 1, 1, 1, 1…
## $ Heating_GasW <dbl> 0, 0, 0, 0, 0, 0…
## $ Heating_Grav <dbl> 0, 0, 0, 0, 0, 0…
## $ Heating_OthW <dbl> 0, 0, 0, 0, 0, 0…
## $ Heating_Wall <dbl> 0, 0, 0, 0, 0, 0…
## $ Heating_QC_Fair <dbl> 0, 0, 0, 0, 0, 0…
## $ Heating_QC_Good <dbl> 0, 0, 1, 0, 0, 0…
## $ Heating_QC_Poor <dbl> 0, 0, 0, 0, 0, 0…
## $ Heating_QC_Typical <dbl> 1, 0, 0, 0, 1, 0…
## $ Central_Air_Y <dbl> 1, 1, 1, 1, 1, 1…
## $ Electrical_FuseF <dbl> 0, 0, 0, 0, 0, 0…
## $ Electrical_FuseP <dbl> 0, 0, 0, 0, 0, 0…
## $ Electrical_Mix <dbl> 0, 0, 0, 0, 0, 0…
## $ Electrical_SBrkr <dbl> 1, 1, 1, 1, 1, 1…
## $ Electrical_Unknown <dbl> 0, 0, 0, 0, 0, 0…
## $ Functional_Maj2 <dbl> 0, 0, 0, 0, 0, 0…
## $ Functional_Min1 <dbl> 0, 0, 0, 0, 1, 0…
## $ Functional_Min2 <dbl> 0, 0, 0, 0, 0, 0…
## $ Functional_Mod <dbl> 0, 0, 0, 0, 0, 0…
## $ Functional_Sal <dbl> 0, 0, 0, 0, 0, 0…
## $ Functional_Sev <dbl> 0, 0, 0, 0, 0, 0…
## $ Functional_Typ <dbl> 1, 1, 1, 1, 0, 1…
## $ Garage_Type_Basment <dbl> 0, 0, 0, 0, 0, 0…
## $ Garage_Type_BuiltIn <dbl> 0, 0, 0, 0, 0, 0…
## $ Garage_Type_CarPort <dbl> 0, 0, 0, 0, 0, 0…
## $ Garage_Type_Detchd <dbl> 0, 0, 0, 1, 0, 0…
## $ Garage_Type_More_Than_Two_Types <dbl> 0, 0, 0, 0, 0, 0…
## $ Garage_Type_No_Garage <dbl> 0, 0, 0, 0, 0, 0…
## $ Garage_Finish_No_Garage <dbl> 0, 0, 0, 0, 0, 0…
## $ Garage_Finish_RFn <dbl> 0, 0, 0, 0, 0, 1…
## $ Garage_Finish_Unf <dbl> 1, 0, 0, 1, 1, 0…
## $ Garage_Cond_Fair <dbl> 0, 0, 0, 0, 0, 0…
## $ Garage_Cond_Good <dbl> 0, 0, 0, 0, 0, 0…
## $ Garage_Cond_No_Garage <dbl> 0, 0, 0, 0, 0, 0…
## $ Garage_Cond_Poor <dbl> 0, 0, 0, 0, 0, 0…
## $ Garage_Cond_Typical <dbl> 1, 1, 1, 1, 1, 1…
## $ Paved_Drive_Partial_Pavement <dbl> 0, 0, 0, 0, 0, 0…
## $ Paved_Drive_Paved <dbl> 1, 1, 1, 1, 1, 1…
## $ Pool_QC_Fair <dbl> 0, 0, 0, 0, 0, 0…
## $ Pool_QC_Good <dbl> 0, 0, 0, 0, 0, 0…
## $ Pool_QC_No_Pool <dbl> 1, 1, 1, 1, 1, 1…
## $ Pool_QC_Typical <dbl> 0, 0, 0, 0, 0, 0…
## $ Fence_Good_Wood <dbl> 0, 0, 0, 0, 0, 0…
## $ Fence_Minimum_Privacy <dbl> 1, 0, 0, 0, 1, 0…
## $ Fence_Minimum_Wood_Wire <dbl> 0, 0, 0, 0, 0, 0…
## $ Fence_No_Fence <dbl> 0, 0, 1, 1, 0, 1…
## $ Misc_Feature_Gar2 <dbl> 0, 0, 0, 0, 0, 0…
## $ Misc_Feature_None <dbl> 1, 0, 1, 1, 1, 1…
## $ Misc_Feature_Othr <dbl> 0, 0, 0, 0, 0, 0…
## $ Misc_Feature_Shed <dbl> 0, 1, 0, 0, 0, 0…
## $ Misc_Feature_TenC <dbl> 0, 0, 0, 0, 0, 0…
## $ Sale_Type_Con <dbl> 0, 0, 0, 0, 0, 0…
## $ Sale_Type_ConLD <dbl> 0, 0, 0, 0, 0, 0…
## $ Sale_Type_ConLI <dbl> 0, 0, 0, 0, 0, 0…
## $ Sale_Type_ConLw <dbl> 0, 0, 0, 0, 0, 0…
## $ Sale_Type_CWD <dbl> 0, 0, 0, 0, 0, 0…
## $ Sale_Type_New <dbl> 0, 0, 0, 0, 0, 0…
## $ Sale_Type_WD. <dbl> 1, 1, 1, 1, 1, 1…
## $ Sale_Condition_AdjLand <dbl> 0, 0, 0, 0, 0, 0…
## $ Sale_Condition_Alloca <dbl> 0, 0, 0, 0, 0, 0…
## $ Sale_Condition_Family <dbl> 0, 0, 0, 0, 0, 0…
## $ Sale_Condition_Normal <dbl> 1, 1, 1, 1, 1, 1…
## $ Sale_Condition_Partial <dbl> 0, 0, 0, 0, 0, 0…
## $ Second_Flr_SF_x_First_Flr_SF <dbl> 0.52453728, -0.0…
## $ Bsmt_Cond_Fair_x_TotRms_AbvGrd <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Cond_Good_x_TotRms_AbvGrd <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Cond_No_Basement_x_TotRms_AbvGrd <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Cond_Poor_x_TotRms_AbvGrd <dbl> 0, 0, 0, 0, 0, 0…
## $ Bsmt_Cond_Typical_x_TotRms_AbvGrd <dbl> -0.9221672, -0.2…5.1.2 Clasificación: Preparación de Datos
Ahora prepararemos los datos para un ejemplo de churn, es decir, la tasa de cancelación de clientes. Usaremos datos de Telco.
telco <- read_csv("data/Churn.csv")
glimpse(telco)## Rows: 7,043
## Columns: 21
## $ customerID <chr> "7590-VHVEG", "5575-GNVDE", "3668-QPYBK", "7795-CFOCW…
## $ gender <chr> "Female", "Male", "Male", "Male", "Female", "Female",…
## $ SeniorCitizen <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ Partner <chr> "Yes", "No", "No", "No", "No", "No", "No", "No", "Yes…
## $ Dependents <chr> "No", "No", "No", "No", "No", "No", "Yes", "No", "No"…
## $ tenure <dbl> 1, 34, 2, 45, 2, 8, 22, 10, 28, 62, 13, 16, 58, 49, 2…
## $ PhoneService <chr> "No", "Yes", "Yes", "No", "Yes", "Yes", "Yes", "No", …
## $ MultipleLines <chr> "No phone service", "No", "No", "No phone service", "…
## $ InternetService <chr> "DSL", "DSL", "DSL", "DSL", "Fiber optic", "Fiber opt…
## $ OnlineSecurity <chr> "No", "Yes", "Yes", "Yes", "No", "No", "No", "Yes", "…
## $ OnlineBackup <chr> "Yes", "No", "Yes", "No", "No", "No", "Yes", "No", "N…
## $ DeviceProtection <chr> "No", "Yes", "No", "Yes", "No", "Yes", "No", "No", "Y…
## $ TechSupport <chr> "No", "No", "No", "Yes", "No", "No", "No", "No", "Yes…
## $ StreamingTV <chr> "No", "No", "No", "No", "No", "Yes", "Yes", "No", "Ye…
## $ StreamingMovies <chr> "No", "No", "No", "No", "No", "Yes", "No", "No", "Yes…
## $ Contract <chr> "Month-to-month", "One year", "Month-to-month", "One …
## $ PaperlessBilling <chr> "Yes", "No", "Yes", "No", "Yes", "Yes", "Yes", "No", …
## $ PaymentMethod <chr> "Electronic check", "Mailed check", "Mailed check", "…
## $ MonthlyCharges <dbl> 29.85, 56.95, 53.85, 42.30, 70.70, 99.65, 89.10, 29.7…
## $ TotalCharges <dbl> 29.85, 1889.50, 108.15, 1840.75, 151.65, 820.50, 1949…
## $ Churn <chr> "No", "No", "Yes", "No", "Yes", "Yes", "No", "No", "Y…Como en el ejemplo de regresión, primero crearemos los conjuntos de entrenamiento y de prueba.
set.seed(1234)
telco_split <- initial_split(telco, prop = .7)
telco_train <- training(telco_split)
telco_test <- testing(telco_split)En el siguiente chunk definiremos la receta con funciones usadas en el ejemplo anterior más la función step_num2factor() que nos ayuda a categorizar una variable continua.
binner <- function(x) {
x <- cut(x, breaks = c(0, 12, 24, 36,48,60,72), include.lowest = TRUE)
as.numeric(x)
}
telco_rec <- recipe(Churn ~ ., data = telco_train) %>%
update_role(customerID, new_role = "id variable") %>%
step_num2factor(tenure, transform = binner,
levels = c("0-1 year", "1-2 years", "2-3 years", "3-4 years", "4-5 years", "5-6 years")) %>%
step_normalize(all_numeric_predictors()) %>%
step_dummy(all_nominal_predictors()) %>%
step_impute_median(all_numeric_predictors()) %>%
step_rm(customerID, skip=T) %>%
prep()Ahora recuperamos la matriz de diseño con las funciones prep() y juice().
telco_juiced <- juice(telco_rec)
telco_juiced## # A tibble: 4,930 × 35
## SeniorCitizen MonthlyCharges TotalCharges Churn gender_Male Partner_Yes
## <dbl> <dbl> <dbl> <fct> <dbl> <dbl>
## 1 -0.442 -1.50 -0.663 No 0 0
## 2 -0.442 0.664 0.472 No 1 1
## 3 -0.442 -0.508 -0.546 No 0 0
## 4 2.26 0.649 -0.850 Yes 0 0
## 5 -0.442 0.167 -0.979 Yes 0 0
## 6 -0.442 0.842 0.975 No 1 1
## 7 -0.442 0.260 -0.648 No 1 0
## 8 -0.442 -0.668 0.178 No 1 1
## 9 -0.442 -1.20 -0.706 No 1 1
## 10 -0.442 -0.407 -0.348 No 0 0
## # … with 4,920 more rows, and 29 more variables: Dependents_Yes <dbl>,
## # tenure_X1.2.years <dbl>, tenure_X2.3.years <dbl>, tenure_X3.4.years <dbl>,
## # tenure_X4.5.years <dbl>, tenure_X5.6.years <dbl>, PhoneService_Yes <dbl>,
## # MultipleLines_No.phone.service <dbl>, MultipleLines_Yes <dbl>,
## # InternetService_Fiber.optic <dbl>, InternetService_No <dbl>,
## # OnlineSecurity_No.internet.service <dbl>, OnlineSecurity_Yes <dbl>,
## # OnlineBackup_No.internet.service <dbl>, OnlineBackup_Yes <dbl>, …telco_test_bake <- bake(telco_rec, new_data = telco_test)
glimpse(telco_test_bake)## Rows: 2,113
## Columns: 36
## $ customerID <chr> "5575-GNVDE", "9305-CDSKC", "671…
## $ SeniorCitizen <dbl> -0.4417148, -0.4417148, -0.44171…
## $ MonthlyCharges <dbl> -0.27067882, 1.14914329, -1.1751…
## $ TotalCharges <dbl> -0.1752116, -0.6472105, -0.87618…
## $ Churn <fct> No, Yes, No, No, No, No, No, No,…
## $ gender_Male <dbl> 1, 0, 0, 1, 1, 0, 1, 1, 1, 1, 0,…
## $ Partner_Yes <dbl> 0, 0, 0, 0, 0, 0, 1, 1, 1, 1, 1,…
## $ Dependents_Yes <dbl> 0, 0, 0, 0, 1, 0, 0, 1, 1, 0, 0,…
## $ tenure_X1.2.years <dbl> 0, 0, 0, 1, 0, 1, 0, 0, 0, 0, 0,…
## $ tenure_X2.3.years <dbl> 1, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ tenure_X3.4.years <dbl> 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,…
## $ tenure_X4.5.years <dbl> 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0,…
## $ tenure_X5.6.years <dbl> 0, 0, 0, 0, 1, 0, 0, 0, 0, 1, 1,…
## $ PhoneService_Yes <dbl> 1, 1, 0, 1, 1, 1, 1, 1, 0, 1, 1,…
## $ MultipleLines_No.phone.service <dbl> 0, 0, 1, 0, 0, 0, 0, 0, 1, 0, 0,…
## $ MultipleLines_Yes <dbl> 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 1,…
## $ InternetService_Fiber.optic <dbl> 0, 1, 0, 0, 1, 1, 0, 0, 0, 0, 1,…
## $ InternetService_No <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0,…
## $ OnlineSecurity_No.internet.service <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0,…
## $ OnlineSecurity_Yes <dbl> 1, 0, 1, 0, 1, 0, 0, 1, 0, 1, 1,…
## $ OnlineBackup_No.internet.service <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0,…
## $ OnlineBackup_Yes <dbl> 0, 0, 0, 0, 0, 1, 0, 1, 1, 1, 1,…
## $ DeviceProtection_No.internet.service <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0,…
## $ DeviceProtection_Yes <dbl> 1, 1, 0, 0, 1, 1, 0, 0, 0, 1, 1,…
## $ TechSupport_No.internet.service <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0,…
## $ TechSupport_Yes <dbl> 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1,…
## $ StreamingTV_No.internet.service <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0,…
## $ StreamingTV_Yes <dbl> 0, 1, 0, 0, 1, 0, 0, 0, 0, 1, 0,…
## $ StreamingMovies_No.internet.service <dbl> 0, 0, 0, 1, 0, 0, 1, 0, 0, 0, 0,…
## $ StreamingMovies_Yes <dbl> 0, 1, 0, 0, 1, 1, 0, 0, 0, 1, 0,…
## $ Contract_One.year <dbl> 1, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0,…
## $ Contract_Two.year <dbl> 0, 0, 0, 1, 1, 0, 0, 0, 0, 1, 1,…
## $ PaperlessBilling_Yes <dbl> 0, 1, 0, 0, 0, 1, 0, 0, 0, 1, 1,…
## $ PaymentMethod_Credit.card..automatic. <dbl> 0, 0, 0, 1, 0, 0, 0, 1, 0, 1, 1,…
## $ PaymentMethod_Electronic.check <dbl> 0, 1, 0, 0, 0, 1, 0, 0, 1, 0, 0,…
## $ PaymentMethod_Mailed.check <dbl> 1, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,…Estos fueron dos ejemplos aplicados de la paquetería recipies, existen distintas funciones step que pueden implementarse en recetas para usarse con tidymodels, en las secciones siguientes les daremos su uso para ajustar un modelo completo.
5.2 Regresión Lineal
En esta sección aprenderemos sobre regresión lineal simple y múltiple, como se ajusta un modelo de regresión en R, las métricas de desempeño para problemas de regresión y como podemos comparar modelos con estas métricas. Existen dos tipos de modelos de regresión lineal:
- Regresión lineal simple: En la regresión lineal simple se utiliza una variable independiente o explicativa “X” (numérica o categórica) para estimar una variable dependiente o de respuesta numérica “Y” mediante el ajuste de una recta permita conocer la relación existente entre ambas variables. Dicha relación entre variables se expresa como:
\[Y = \beta_0 + \beta_1X_1 + \epsilon \approx b + mx\] Donde:
\(\epsilon \sim Norm(0,\sigma^2)\) (error aleatorio)
\(\beta_0\) = Coeficiente de regresión 0 (Ordenada al origen o intercepto)
\(\beta_1\) = Coeficiente de regresión 1 (Pendiente o regresor de variable \(X_1\))
\(X_1\) = Variable explicativa observada
\(Y\) = Respuesta numérica
Debido a que los valores reales de \(\beta_0\) y \(\beta_1\) son desconocidos, procedemos a estimarlos estadísticamente:
\[\hat{Y} = \hat{\beta}_0 + \hat{\beta}_1X_1\] Con \(\hat{\beta}_0\) el estimado de la ordenada al origen y \(\hat{\beta}_1\) el estimado de la pendiente.
- Regresión lineal múltiple: Cuando se utiliza más de una variable independiente, el proceso se denomina regresión lineal múltiple. En este escenario no es una recta sino un hiper-plano lo que se ajusta a partir de las covariables explicativas \(\{X_1, X_2, X_3, ...,X_n\}\)
El objetivo de un modelo de regresión múltiple es tratar de explicar la relación que existe entre una variable dependiente (variable respuesta) \("Y"\) un conjunto de variables independientes (variables explicativas) \(\{X1,..., Xm\}\), el modelo es de la forma:
\[Y = \beta_0 + \beta_1X_1 + \cdot \cdot \cdot + \beta_mX_m + \epsilon\]
Donde:
\(Y\) como variable respuesta.
\(X_1,X_2,...,X_m\) como las variables explicativas, independientes o regresoras.
\(\beta_1, \beta_2,...,\beta_m\) Se conocen como coeficientes parciales de regresión. Cada una de ellas puede interpretarse como el efecto promedio que tiene el incremento de una unidad de la variable predictora \(X_i\) sobre la variable dependiente \(Y\), manteniéndose constantes el resto de variables.
5.2.1 Ajuste de modelo
5.2.1.1 Estimación de parámetros: Regresión lineal simple
En la gran mayoría de casos, los valores \(\beta_0\) y \(\beta_1\) poblacionales son desconocidos, por lo que, a partir de una muestra, se obtienen sus estimaciones \(\hat{\beta_0}\) y \(\hat{\beta_1}\). Estas estimaciones se conocen como coeficientes de regresión o least square coefficient estimates, ya que toman aquellos valores que minimizan la suma de cuadrados residuales, dando lugar a la recta que pasa más cerca de todos los puntos.

En términos analíticos, la expresión matemática a optimizar y solución están dadas por:
\[min(\epsilon) \Rightarrow min(y-\hat{y}) = min\{y -(\hat{\beta}_0 + \hat{\beta}_1x)\}\]
\[\begin{aligned} \hat{\beta}_0 &= \overline{y} - \hat{\beta}_1\overline{x} \\ \hat{\beta}_1 &= \frac{\sum^n_{i=1}(x_i - \overline{x})(y_i - \overline{y})}{\sum^n_{i=1}(x_i - \overline{x})^2} =\frac{S_{xy}}{S^2_x} \end{aligned}\]Donde:
\(S_{xy}\) es la covarianza entre \(x\) y \(y\).
\(S_{x}^{2}\) es la varianza de \(x\).
\(\hat{\beta}_0\) es el valor esperado la variable \(Y\) cuando \(X = 0\), es decir, la intersección de la recta con el eje y.
5.2.1.2 Estimación de parámetros: Regresión lineal múltiple
En el caso de múltiples parámetros, la notación se vuelve más sencilla al expresar el modelo mediante una combinación lineal dada por la multiplicación de matrices (álgebra lineal).
\[Y = X\beta + \epsilon\]
Donde:
\[Y = \begin{pmatrix}y_1\\y_2\\.\\.\\.\\y_n\end{pmatrix} \quad \beta = \begin{pmatrix}\beta_0\\\beta_1\\.\\.\\.\\\beta_m\end{pmatrix} \quad \epsilon = \begin{pmatrix}\epsilon_1\\\epsilon_2\\.\\.\\.\\\epsilon_n\end{pmatrix} \quad \quad X = \begin{pmatrix}1 & x_{11} & x_{12} & ... & x_{1m}\\1 & x_{21} & x_{22} & ... & x_{2m}\\\vdots & \vdots & \vdots & \ddots & \vdots\\ 1 & x_{n1} & x_{n2} & ... & x_{nm}\end{pmatrix}\\\]
El estimador por mínimos cuadrados está dado por:
\[\hat{\beta} = (X^TX)^{-1}X^TY\]
IMPORTANTE: Es necesario entender que para cada uno de los coeficientes de regresión se realiza una prueba de hipótesis. Una vez calculado el valor estimado, se procede a determinar si este valor es significativamente distinto de cero, por lo que la hipótesis de cada coeficiente se plantea de la siguiente manera:
\[H_0:\beta_i=0 \quad Vs \quad H_1:\beta_i\neq0\] El software R nos devuelve el p-value asociado a cada coeficiente de regresión. Recordemos que valores pequeños de p sugieren que al rechazar \(H_0\), la probabilidad de equivocarnos es baja, por lo que procedemos a rechazar la hipótesis nula.
5.2.2 Residuos del modelo
El residuo de una estimación se define como la diferencia entre el valor observado y el valor esperado acorde al modelo.
\[\epsilon_i= y_i -\hat{y}_i\]
A la hora de contemplar el conjunto de residuos hay dos posibilidades:
- La suma del valor absoluto de cada residuo.
\[RAS=\sum_{i=1}^{n}{|e_i|}=\sum_{i=1}^{n}{|y_i-\hat{y}_i|}\]
- La suma del cuadrado de cada residuo (RSS). Esta es la aproximación más empleada (mínimos cuadrados) ya que magnifica las desviaciones más extremas.
\[RSS=\sum_{i=1}^{n}{e_i^2}=\sum_{i=1}^{n}{(y_i-\hat{y}_i)^2}\]
Los residuos son muy importantes puesto que en ellos se basan las diferentes métricas de desempeño del modelo.
5.2.2.1 Condiciones para el ajuste de una regresión lineal:
Existen ciertas condiciones o supuestos que deben ser validados para el correcto ajuste de un modelo de regresión lineal, los cuales se enlistan a continuación:
Linealidad: La relación entre ambas variables debe ser lineal.
Distribución normal de los residuos: Los residuos se tiene que distribuir de forma normal, con media igual a 0.
Varianza de residuos constante (homocedasticidad): La varianza de los residuos tiene que ser aproximadamente constante.
Independencia: Las observaciones deben ser independientes unas de otras.
Dado que las condiciones se verifican a partir de los residuos, primero se suele generar el modelo y después se valida.
5.2.3 Métricas de desempeño
Dado que nuestra variable a predecir es numérica, podemos medir qué tan cerca o lejos estuvimos del número esperado dada una predicción.
Las métricas de desempeño asociadas a los problemas de regresión ocupan esa distancia cómo cuantificación del desempeño o de los errores cometidos por el modelo.
Las métricas más utilizadas son:
- MEA: Mean Absolute Error
- MAPE: Mean Absolute Percentual Error \(\quad \Rightarrow \quad\) más usada para reportar resultados
- RMSE: Root Mean Squared Error \(\quad \quad \quad \Rightarrow \quad\) más usada para entrenar modelos
- \(R^2\) : R cuadrada
- \(R^2\) : \(R^2\) ajustada
- RMSLE: Root Mean Squared Logarithmic Loss Error
MAE: Mean Absolute Error
\[MAE = \frac{1}{N}\sum_{i=1}^{N}{|y_{i}-\hat{y}_{i}|}\] Donde:
- \(N:\) Número de observaciones predichas.
- \(y_{i}:\) Valor real.
- \(\hat{y}_{i}:\) Valor de la predicción.
Esta métrica suma los errores absolutos de cada predicción y los divide entre el número de observaciones, para obtener el promedio absoluto del error del modelo.
Ventajas Vs Desventajas:
Todos los errores pesan lo mismo sin importar qué tan pequeños o qué tan grandes sean, es muy sensible a valores atípicos, y dado que obtiene el promedio puede ser que un solo error en la predicción que sea muy grande afecte al valor de todo el modelo, aún y cuando el modelo no tuvo errores tan malos para el resto de las observaciones.
Se recomienda utilizar esta métrica cuando los errores importan lo mismo, es decir, importa lo mismo si se equivocó muy poco o se equivocó mucho.
MAPE: Mean Absolute Percentage Error
\[MAPE = \frac{1}{N}\sum_{i=1}^{N}\frac{{|y_{i}-\hat{y}_{i}|}}{|y_{i}|}\] Donde:
\(N:\) Número de observaciones predichas.
\(y_{i}:\) Valor real.
\(\hat{y}_{i}:\) Valor de la predicción.
Esta métrica es la métrica MAE expresada en porcentaje, por lo que mide el error del modelo en términos de porcentaje, al igual que con MAE, no hay errores negativos por el valor absoluto, y mientras más pequeño el error es mejor.
Ventajas Vs Desventajas:
Cuando existe un valor real de 0 esta métrica no se puede calcular, por otro lado, una de las ventajas sobre MAE es que no es sensible a valores atípicos.
Se recomienda utilizar esta métrica cuando en tu problema no haya valores a predecir que puedan ser 0, por ejemplo, en ventas puedes llegar a tener 0 ventas, en este caso no podemos ocupar esta métrica.
En general a las personas de negocio les gusta esta métrica pues es fácil de comprender.
RMSE: Root Mean Squared Error
\[RMSE = \sqrt{\frac{1}{N}\sum_{i=1}^{N}{(y_{i}-\hat{y}_{i})^2}}\] Donde:
- \(N:\) Número de observaciones predichas.
- \(y_{i}:\) Valor real.
- \(\hat{y}_{i}:\) Valor de la predicción.
Esta métrica es muy parecida a MAE, solo que en lugar de sacar el valor absoluto de la diferencia entre el valor real y el valor predicho, para evitar valores negativos eleva esta diferencia al cuadrado, y saca el promedio de esa diferencia, al final, para dejar el valor en la escala inicial saca la raíz cuadrada.
Esta es la métrica más utilizada en problemas de regresión, debido a que es más fácil de optimizar que el MAE.
Ventajas Vs Desventaja:
Todos los errores pesan lo mismo sin importar qué tan pequeños o qué tan grandes sean, es más sensible a valores atípicos que MAE pues eleva al cuadrado diferencias, y dado que obtiene el promedio puede ser que un solo error en la predicción que sea muy grande afecte al valor de todo el modelo, aún y cuando el modelo no tuvo errores tan malos para el resto de las observaciones.
Se recomienda utilizar esta métrica cuando en el problema que queremos resolver es muy costoso tener equivocaciones grandes, podemos tener varios errores pequeños, pero no grandes.
\(R^2\): R cuadrada
\[R^{2} = \frac{\sum_{i=1}^{N}{(\hat{y}_{i}-\bar{y}_{i})^2}}{\sum_{i=1}^{N}{(y_{i}-\bar{y}_{i})^2}}\] Donde:
- \(N:\) Número de observaciones predichas.
- \(y_{i}:\) Valor real.
- \(\hat{y}_{i}:\) Valor de la predicción.
- \(\bar{y}_{i}:\) Valor promedio de la variable y.
El coeficiente de determinación es la proporción de la varianza total de la variable explicada por la regresión. El coeficiente de determinación, también llamado R cuadrado, refleja la bondad del ajuste de un modelo a la variable que pretender explicar.
Es importante saber que el resultado del coeficiente de determinación oscila entre 0 y 1. Cuanto más cerca de 1 se sitúe su valor, mayor será el ajuste del modelo a la variable que estamos intentando explicar. De forma inversa, cuanto más cerca de cero, menos ajustado estará el modelo y, por tanto, menos fiable será.
Ventajas Vs Desventaja:
El problema del coeficiente de determinación, y razón por el cual surge el coeficiente de determinación ajustado, radica en que no penaliza la inclusión de variables explicativas no significativas, es decir, el valor de \(R^2\) siempre será más grande cuantas más variables sean incluidas en el modelo, aún cuando estas no sean significativas en la predicción.
\(\bar{R}^2\): \(R^2\) ajustada
\[\bar{R}^2=1-\frac{N-1}{N-k-1}[1-R^2]\] Donde:
- \(\bar{R}²:\) Es el valor de R² ajustado
- \(R²:\) Es el valor de R² original
- \(N:\) Es el total de observaciones en el ajuste
- \(k:\) Es el número de variables usadas en el modelo
El coeficiente de determinación ajustado (R cuadrado ajustado) es la medida que define el porcentaje explicado por la varianza de la regresión en relación con la varianza de la variable explicada. Es decir, lo mismo que el R cuadrado, pero con una diferencia: El coeficiente de determinación ajustado penaliza la inclusión de variables.
En la fórmula, N es el tamaño de la muestra y k el número de variables explicativas.
RMSLE: Root Mean Squared Logarithmic Loss Error
\[e = \sqrt{\frac{1}{n}\sum_{i=1}^{n} (log(1+p_i)-log(1+o_i))^2}\]
Donde: \(p_i\) son las predicciones y \(o_i\) son las observaciones, esto implica que nos interesa más evaluar error relativo que absoluto, pues:
\[log(1+p)-log(1+o)=log(\frac{1+p}{1+o})\approx log(\frac{p}{o})=log(1+\frac{p-o}{o})\approx\frac{p-o}{p}\]
Ventajas Vs Desventaja:
Suele ser más complicada el entendimiento de esta métrica, a diferencia de las métricas anteriores, sin embargo, esta métrica realiza la penalización de los errores grandes al mismo tiempo que apromixa a al error relativo (\(\approx\) raiz de error relativo cuadrático medio).
5.2.4 Implementación en R
Ajustaremos un modelo de regresión usando la receta antes vista.
library(tidymodels)
modelo1 <- linear_reg() %>%
set_mode("regression") %>%
set_engine("lm")
lm_fit1 <- fit(modelo1, Sale_Price ~ ., casa_juiced)
p_test <- predict(lm_fit1, casa_test_bake) %>%
mutate(.pred = exp(.pred)) %>%
bind_cols(ames_test) %>%
select(.pred, Sale_Price) %>%
mutate(error = Sale_Price - .pred)
p_test## # A tibble: 733 × 3
## .pred Sale_Price error
## <dbl> <int> <dbl>
## 1 116703. 105000 -11703.
## 2 177029. 185000 7971.
## 3 166772. 180400 13628.
## 4 109872. 141000 31128.
## 5 219261. 210000 -9261.
## 6 212340. 216000 3660.
## 7 164850. 149900 -14950.
## 8 99545. 105500 5955.
## 9 102023. 88000 -14023.
## 10 137758. 146000 8242.
## # … with 723 more rows5.2.5 Coeficientes del modelo
Podemos recuperar los coeficientes de nuestro modelo con la función tidy() y observar cuales variables explicativas son las más significativas de acuerdo con el p-value.
lm_fit1 %>% tidy() %>% arrange(desc(p.value))## # A tibble: 275 × 5
## term estimate std.error statistic p.value
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 Roof_Style_Gambrel -3.73e-4 0.0778 -0.00479 0.996
## 2 Exterior_1st_Stone -7.39e-4 0.141 -0.00524 0.996
## 3 House_Style_Two_Story 3.78e-4 0.0281 0.0135 0.989
## 4 Neighborhood_South_and_West_of_Iowa_Sta… -5.82e-4 0.0369 -0.0158 0.987
## 5 Exterior_2nd_HdBoard -1.17e-3 0.0520 -0.0224 0.982
## 6 Bsmt_Cond_Typical -2.76e-3 0.0799 -0.0346 0.972
## 7 Electrical_Unknown 4.00e-3 0.111 0.0362 0.971
## 8 Latitude -5.38e-4 0.0142 -0.0380 0.970
## 9 Neighborhood_Mitchell 1.66e-3 0.0421 0.0395 0.968
## 10 Neighborhood_Sawyer 1.64e-3 0.0331 0.0494 0.961
## # … with 265 more rows5.2.6 Métricas de desempeño
Ahora para calcular las métricas de desempeño usaremos la paqueteria MLmetrics y las funciones de dplyr para resumir y estructurar los resultados.
library(MLmetrics)
p_test %>%
summarise(
MAE = MLmetrics::MAE(.pred, Sale_Price),
MAPE = MLmetrics::MAPE(.pred, Sale_Price),
RMSE = MLmetrics::RMSE(.pred, Sale_Price),
R2 = MLmetrics::R2_Score(.pred, Sale_Price),
RMSLE = MLmetrics::RMSLE(.pred, Sale_Price)
) ## # A tibble: 1 × 5
## MAE MAPE RMSE R2 RMSLE
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 16515. 0.0951 26794. 0.889 0.2075.2.6.1 Gráfica de ajuste
library(patchwork)
pred_obs_plot <- p_test %>%
ggplot(aes(x = .pred, y = Sale_Price)) +
geom_point(alpha = 0.2) + geom_abline(color = "red") +
xlab("Predicciones") + ylab("Observaciones") +
ggtitle("Predicción vs Observación")
error_line <- p_test %>%
ggplot(aes(x = Sale_Price, y = error)) +
geom_line() + geom_hline(yintercept = 0, color = "red") +
xlab("Observaciones") + ylab("Errores") +
ggtitle("Varianza de errores")
pred_obs_plot + error_line
error_dist <- p_test %>%
ggplot(aes(x = error)) +
geom_histogram(color = "white", fill = "black") +
geom_vline(xintercept = 0, color = "red") +
ylab("Conteos de clase") + xlab("Errores") +
ggtitle("Distribución de error")
error_qqplot <- p_test %>%
ggplot(aes(sample = error)) +
geom_qq(alpha = 0.3) + stat_qq_line(color = "red") +
xlab("Distribución normal") + ylab("Distribución de errores") +
ggtitle("QQ-Plot")
error_dist + error_qqplot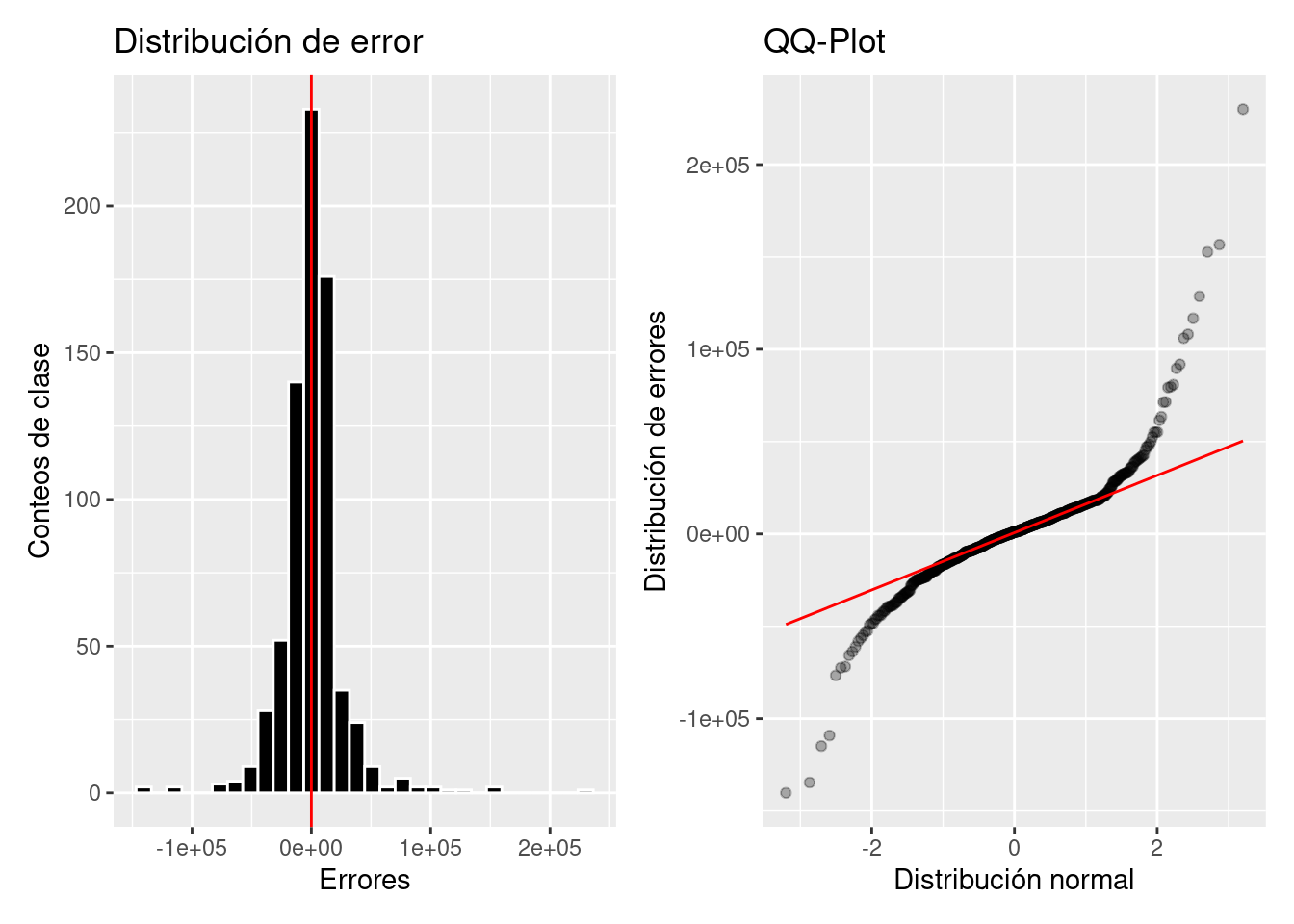
5.2.7 Métodos se selección de variables
5.2.7.1 Forward selection (selección hacia adelante)
Comienza sin predictores en el modelo, agrega iterativamente los predictores más contribuyentes y se detiene cuando la mejora del modelo ya no es estadísticamente significativa.

5.2.7.2 Backward selection (selección hacia atrás)
Comienza con todos los predictores en el modelo (modelo completo), y elimina iterativamente los predictores menos contribuyentes y se detiene cuando tiene un modelo en el que todos los predictores son estadísticamente significativos.
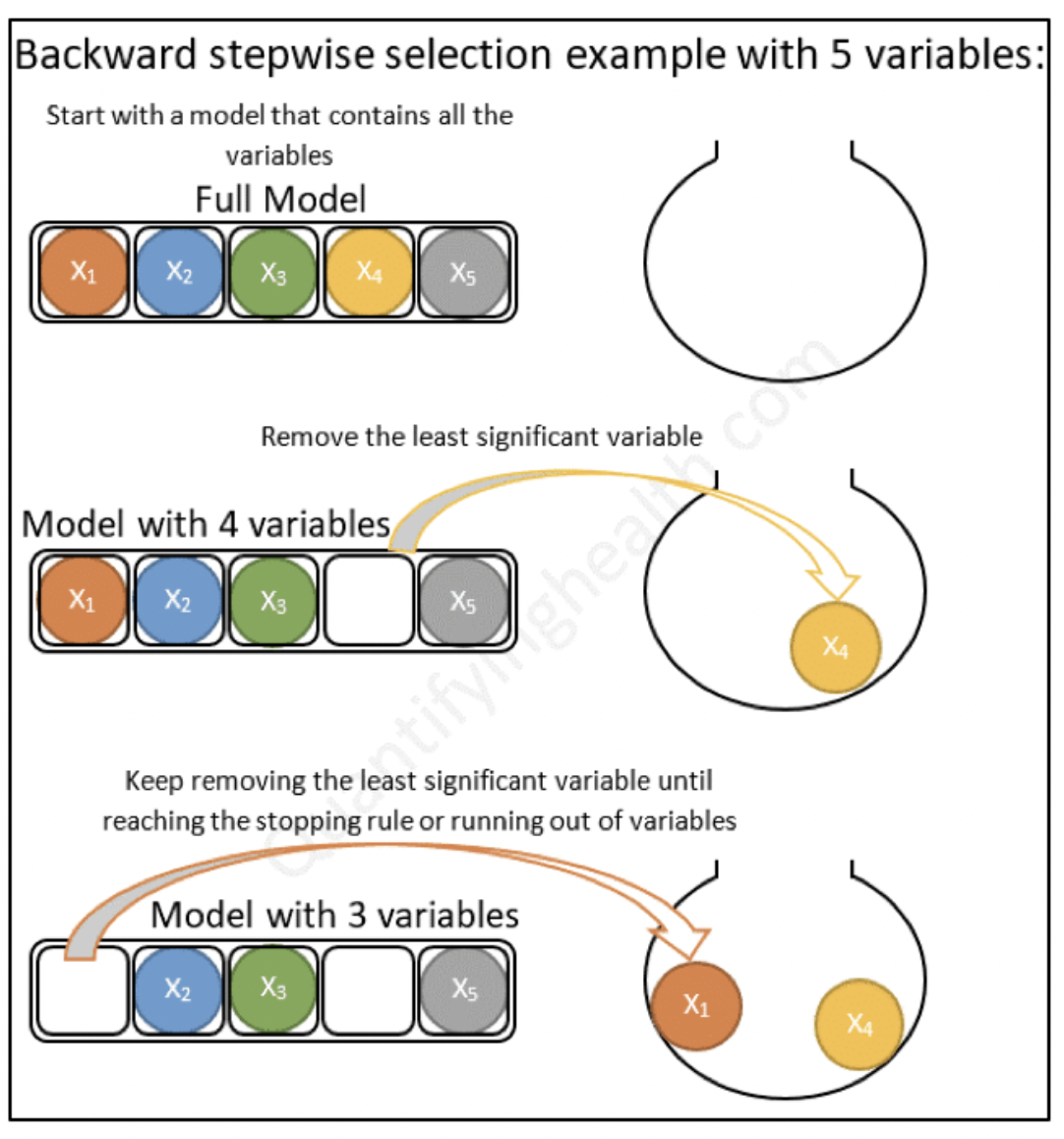
5.2.7.3 Stepwise selection (selección paso a paso)
Combinación de selecciones hacia adelante y hacia atrás. Comienza sin predictores, luego agrega secuencialmente los predictores más contribuyentes (como la selección hacia adelante). Después de agregar cada nueva variable, elimina cualquier variable que ya no proporcione una mejora en el ajuste del modelo (como la selección hacia atrás).
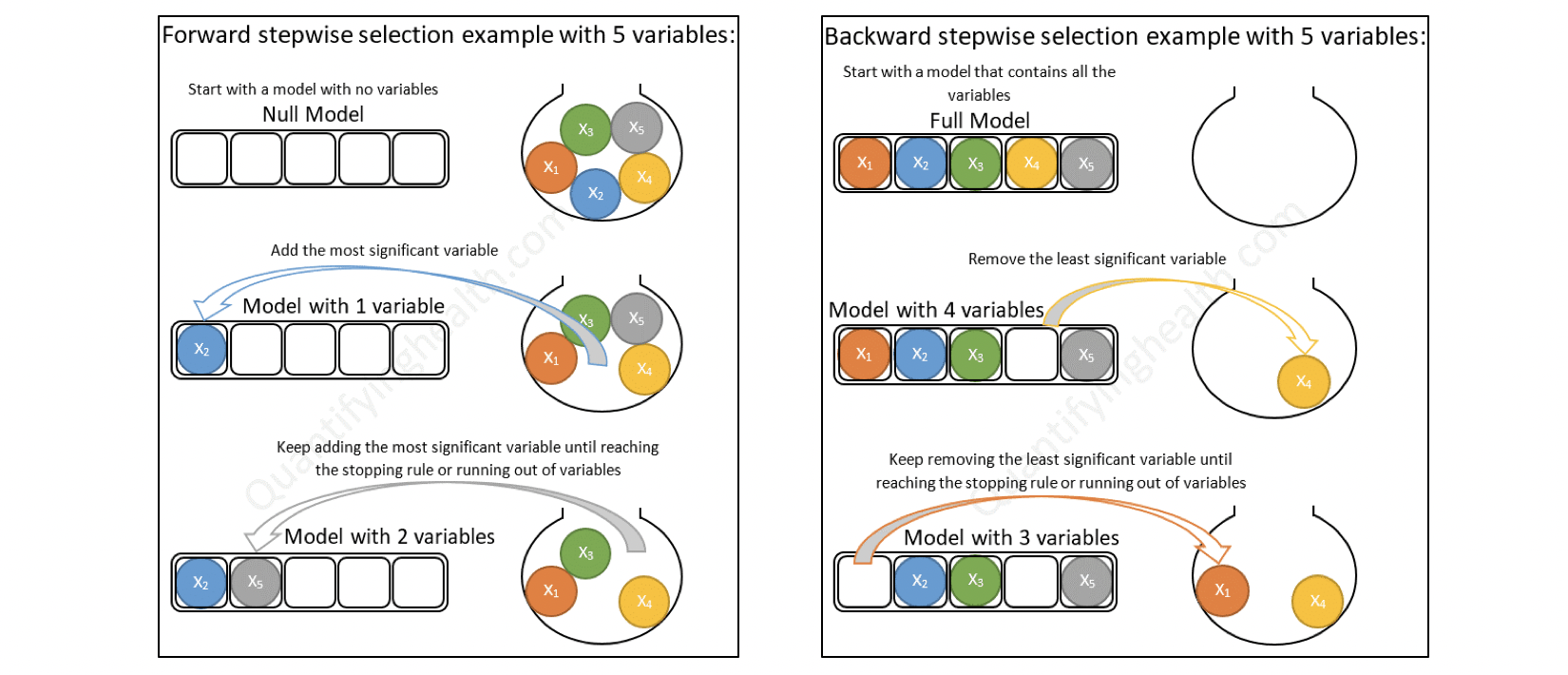
5.2.7.4 Desventajas de la selección forward, backward y stepwise
Inflación de resultados falsos positivos: la selección hacia adelante, hacia atrás y paso a paso utiliza muchas pruebas de hipótesis repetidas para tomar decisiones sobre la inclusión o exclusión de predictores individuales. Los valores \(p\) correspondientes no están ajustados, lo que lleva a una selección excesiva de características (es decir, resultados falsos positivos). Además, este problema se agrava cuando están presentes predictores altamente correlacionados.
Sobreajuste del modelo: Las estadísticas del modelo resultante, incluidas las estimaciones de los parámetros y la incertidumbre asociada, son muy optimistas ya que no tienen en cuenta el proceso de selección.
5.3 Regresión Logística
El nombre de este modelo es: Regresión Bernoulli con liga logit, pero todo mundo la conoce solo por regresión logística. Es importante saber que la liga puede ser elegida dentro de un conjunto de ligas comunes, por lo que puede dejar de ser logit y seguir siendo regresión Bernoulli, pero ya no podría ser llamada “logística.”
Al igual que en regresión lineal, existe la regresión simple y regresión múltiple. La regresión logística simple se utiliza una variable independiente, mientras que cuando se utiliza más de una variable independiente, el proceso se denomina regresión logística múltiple.
Objetivo: Estimar la probabilidad de pertenecer a la categoría positiva de una variable de respuesta categórica. Posteriormente, se determina el umbral de probabilidad a partir del cual se clasifica a una observación como positiva o negativa.
5.3.1 Función sigmoide
Si una variable cualitativa con dos categorías se codifica como 1 y 0, matemáticamente es posible ajustar un modelo de regresión lineal por mínimos cuadrados. El problema de esta aproximación es que, al tratarse de una recta, para valores extremos del predictor, se obtienen valores de \(Y\) menores que 0 o mayores que 1, lo que entra en contradicción con el hecho de que las probabilidades siempre están dentro del rango [0,1].
Para evitar estos problemas, la regresión logística transforma el valor devuelto por la regresión lineal empleando una función cuyo resultado está siempre comprendido entre 0 y 1. Existen varias funciones que cumplen esta descripción, una de las más utilizadas es la función logística (también conocida como función sigmoide):
\[\sigma(Z)=\frac{e^{Z}}{1+e^{Z}}\] Función sigmoide:
Para valores de \(Z\) muy grandes, el valor de \(e^{Z}\) tiende a infinito por lo que el valor de la función sigmoide es 1. Para valores de \(Z\) muy negativos, el valor \(e^{Z}\) tiende a cero, por lo que el valor de la función sigmoide es 0.
Sustituyendo la \(Z\) de la función sigmoide por la función lineal \(\beta_0+\beta_1X\) se obtiene que:
\[\pi=P(Y=k|X=x)=\frac{e^{\beta_0+\beta_1X}}{1+e^{\beta_0+\beta_1X}}\]
donde \(P(Y=k|X=x)\) puede interpretarse como: la probabilidad de que la variable cualitativa \(Y\) adquiera el valor \(k\), dado que el predictor \(X\) tiene el valor \(x\).
5.3.2 Ajuste del modelo
Esta función, puede ajustarse de forma sencilla con métodos de regresión lineal si se emplea su versión logarítmica:
\[logit(\pi)= ln(\frac{\pi}{1-\pi}) = ln(\frac{p(Y=k|X=x)}{1−p(Y=k|X=x)})=\beta_0+\beta_1X\]
\[P(Y=k|X=x)=\frac{e^{\beta_0+\beta_1x_1+\beta_2x_2+...+\beta_ix_i}}{1+e^{\beta_0+\beta_1x_1+\beta_2x_2+...+\beta_ix_i}}\]
La combinación óptima de coeficientes \(\beta_0\) y \(\beta_1\) será aquella que tenga la máxima verosimilitud (maximum likelihood), es decir el valor de los parámetros \(\beta_0\) y \(\beta_1\) con los que se maximiza la probabilidad de obtener los datos observados.
El método de maximum likelihood está ampliamente extendido en la estadística aunque su implementación no siempre es trivial.
Otra forma para ajustar un modelo de regresión logística es empleando descenso de gradiente. Si bien este no es el método de optimización más adecuado para resolver la regresión logística, está muy extendido en el ámbito de machine learning para ajustar otros modelos.
5.3.3 Clasificación
Una de las principales aplicaciones de un modelo de regresión logística es clasificar la variable cualitativa en función de valor que tome el predictor. Para conseguir esta clasificación, es necesario establecer un threshold de probabilidad a partir de la cual se considera que la variable pertenece a uno de los niveles. Por ejemplo, se puede asignar una observación al grupo 1 si \(p̂ (Y=1|X)>0.3\) y al grupo 0 si ocurre lo contrario.
Es importante mencionar que el punto de corte no necesariamente tiene que ser 0.5, este puede ser seleccionado a convenecía de la métrica a optimizar.
5.3.4 Métricas de desempeño
Existen distintas métricas de desempeño para problemas de clasificación, debido a que contamos con la respuesta correcta podemos contar cuántos aciertos tuvimos y cuántos fallos tuvimos.
Primero, por simplicidad ocuparemos un ejemplo de clasificación binaria, Cancelación (1) o No Cancelación (0).
En este tipo de algoritmos definimos cuál de las categorías será nuestra etiqueta positiva y cuál será la negativa. La positiva será la categoría que queremos predecir -en nuestro ejemplo, Cancelación- y la negativa lo opuesto -en el caso binario- en nuestro ejemplo, no cancelación.
Dadas estas definiciones tenemos 4 posibilidades:
True positives: Nuestra predicción dijo que la transacción es fraude y la etiqueta real dice que es fradue.
False positives: Nuestra predicción dijo que la transacción es fraude y la etiqueta real dice que no es fraude.
True negatives: Nuestra predicción dijo que la transacción es no fraude y la etiqueta real dice que no es fraude.
False negatives: Nuestra predicción dijo que la transacción es no fraude y la etiqueta real dice que es fraude.
Matriz de confusión

Esta métrica corresponde a una matriz en donde se plasma el conteo de los aciertos y los errores que haya hecho el modelo, esto es: los verdaderos positivos (TP), los verdaderos negativos (TN), los falsos positivos (FP) y los falsos negativos (FN).
Normalmente los renglones representan las etiquetas predichas, ya sean positivas o negativas, y las columnas a las etiquetas reales, aunque esto puede cambiar en cualquier software.
- Accuracy
Número de aciertos totales entre todas las predicciones.
\[accuracy = \frac{TP + TN}{ TP+FP+TN+FN}\]
La métrica más utilizada, en datasets no balanceados esta métrica no nos sirve, al contrario, nos engaña. Adicionalmente, cuando la identificación de una categoría es más importante que otra es mejor recurrir a otras métricas.
- Precision: Eficiencia
De los que identificamos como clase positiva, cuántos identificamos correctamente. ¿Qué tan eficientes somos en la predicción?
\[precision = \frac{TP}{TP + FP}\]
¿Cuándo utilizar precision?
Esta es la métrica que ocuparás más, pues en un contexto de negocio, donde los recursos son finitos y tiene un costo asociado, ya sea monetario o de tiempo o de recursos, necesitarás que las predicciones de tu etiqueta positiva sean muy eficientes.
Al utilizar esta métrica estaremos optimizando el modelo para minimizar el número de falsos positivos.
- Recall o Sensibilidad: Cobertura
Del universo posible de nuestra clase positiva, cuántos identificamos correctamente.
\[recall = \frac{TP}{TP + FN }\]
Esta métrica la ocuparás cuando en el contexto de negocio de tu problema sea más conveniente aumentar la cantidad de positivos o disminuir los falsos negativos. Esto se realiza debido al impacto que estos pueden tener en las personas en quienes se implementará la predicción.
- Especificidad
Es el número de observaciones correctamente identificados como negativos fuera del total de negativos.
\[Specificity = \frac{TN}{TN+FP}\]
- F1-score
Combina precision y recall para optimizar ambos.
\[F = 2 *\frac{precision * recall}{precision + recall} \]
Se recomienda utilizar esta métrica de desempeño cuando quieres balancear tanto los falsos positivos como los falsos negativos. Aunque es una buena solución para tomar en cuenta ambos errores, pocas veces hay problemas reales que permiten ocuparla, esto es porque en más del 90% de los casos tenemos una restricción en recursos.
Ahora con esto en mente podemos definir las siguientes métricas:
- AUC y ROC: Area Under the Curve y Receiver operator characteristic
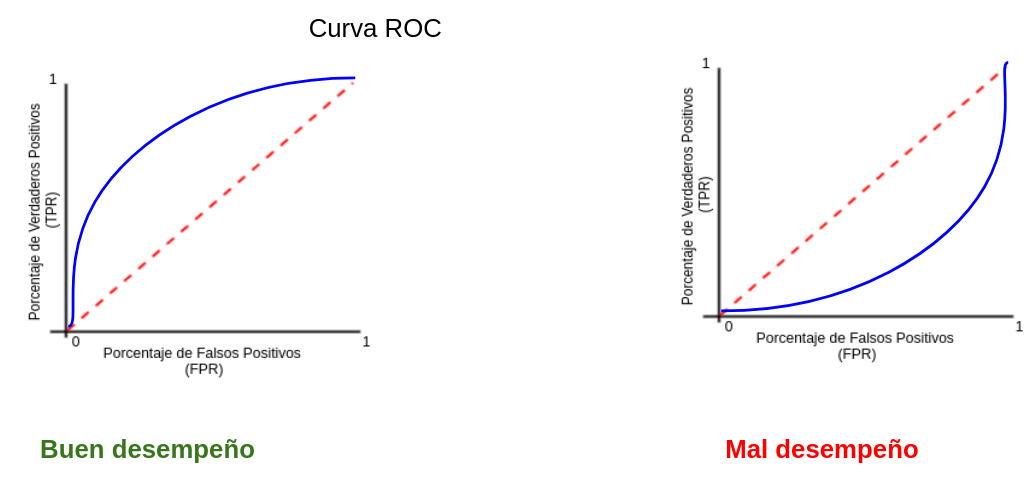
Una curva ROC es un gráfico que muestra el desempeño de un modelo de clasificación en todos los puntos de corte.
AUC significa “Área bajo la curva ROC.” Es decir, AUC mide el área debajo de la curva ROC.
5.3.5 Implementación en R
Ajustaremos un modelo de regresión logística usando la receta antes vista.
logistic_model <- logistic_reg() %>%
set_engine("glm")
logistic_fit1 <- parsnip::fit(logistic_model, Churn ~ ., telco_juiced)
logistic_p_test <- predict(logistic_fit1, telco_test_bake) %>%
bind_cols(telco_test_bake) %>%
select(.pred_class, Churn)
logistic_p_test## # A tibble: 2,113 × 2
## .pred_class Churn
## <fct> <fct>
## 1 No No
## 2 Yes Yes
## 3 No No
## 4 No No
## 5 No No
## 6 Yes No
## 7 No No
## 8 No No
## 9 No Yes
## 10 No No
## # … with 2,103 more rows5.3.6 Métricas de desempeño
Matriz de Confusión
logistic_p_test %>%
yardstick::conf_mat(truth = Churn, estimate = .pred_class) %>%
autoplot(type = "heatmap")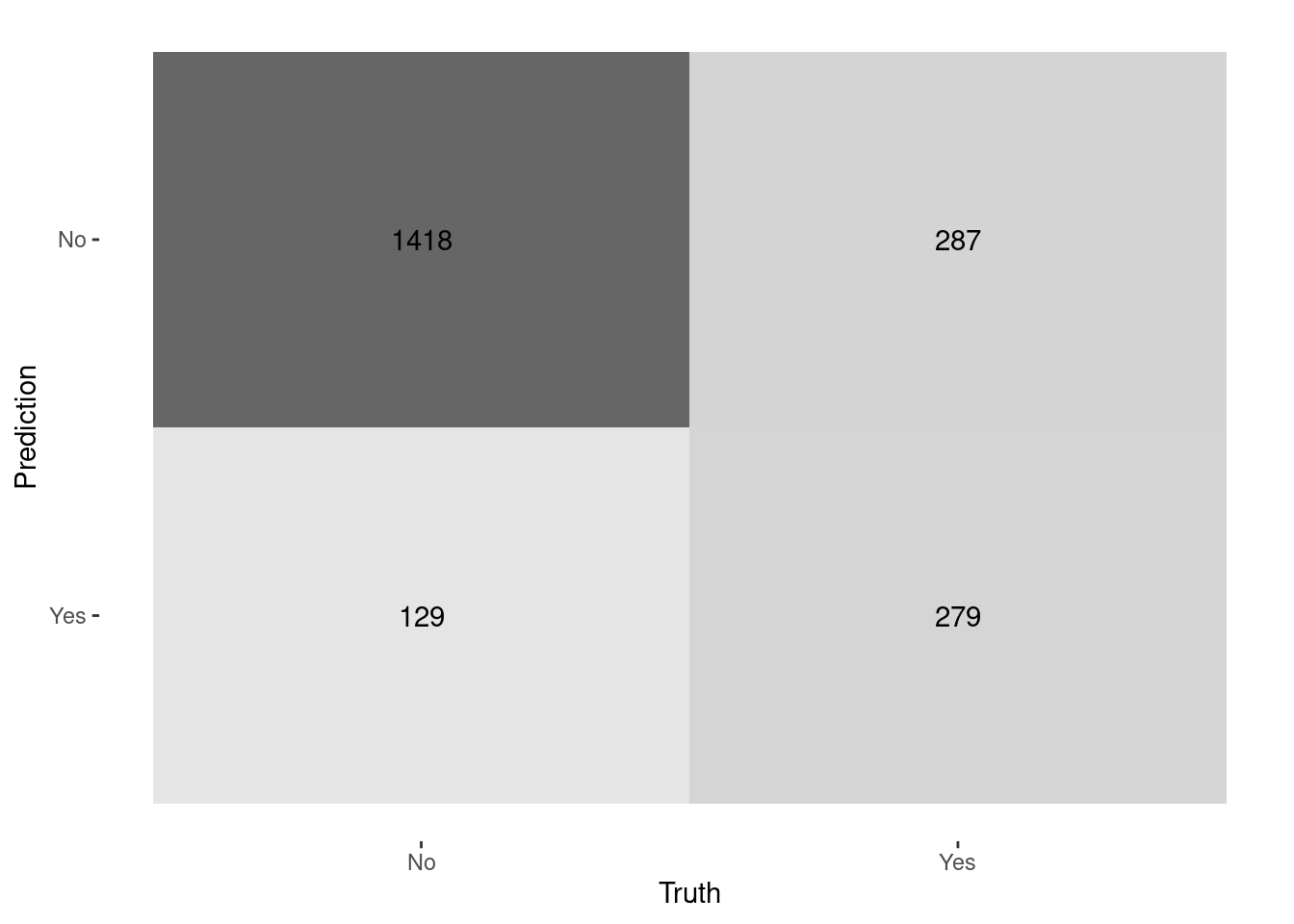
bind_rows(
yardstick::accuracy(logistic_p_test, Churn, .pred_class, event_level = "second"),
yardstick::precision(logistic_p_test, Churn, .pred_class, event_level = "second"),
yardstick::recall(logistic_p_test, Churn, .pred_class, event_level = "second"),
yardstick::specificity(logistic_p_test, Churn, .pred_class, event_level = "second"),
yardstick::f_meas(logistic_p_test, Churn, .pred_class, event_level = "second")
)## # A tibble: 5 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 accuracy binary 0.803
## 2 precision binary 0.684
## 3 recall binary 0.493
## 4 spec binary 0.917
## 5 f_meas binary 0.573¿Y si se quiere un corte diferente? ¿el negocio qué necesita?
logistic_p_test_prob <- predict(logistic_fit1, telco_test_bake, type = "prob") %>%
bind_cols(telco_test_bake) %>%
select(.pred_Yes, .pred_No, Churn)
logistic_p_test_prob## # A tibble: 2,113 × 3
## .pred_Yes .pred_No Churn
## <dbl> <dbl> <fct>
## 1 0.0367 0.963 No
## 2 0.837 0.163 Yes
## 3 0.335 0.665 No
## 4 0.0130 0.987 No
## 5 0.0348 0.965 No
## 6 0.509 0.491 No
## 7 0.0753 0.925 No
## 8 0.0449 0.955 No
## 9 0.424 0.576 Yes
## 10 0.0187 0.981 No
## # … with 2,103 more rowslogistic_p_test_prob <- logistic_p_test_prob %>%
mutate(.pred_class = as_factor(if_else ( .pred_Yes >= 0.30, 'Yes', 'No'))) %>%
relocate(.pred_class , .after = .pred_No)
logistic_p_test_prob## # A tibble: 2,113 × 4
## .pred_Yes .pred_No .pred_class Churn
## <dbl> <dbl> <fct> <fct>
## 1 0.0367 0.963 No No
## 2 0.837 0.163 Yes Yes
## 3 0.335 0.665 Yes No
## 4 0.0130 0.987 No No
## 5 0.0348 0.965 No No
## 6 0.509 0.491 Yes No
## 7 0.0753 0.925 No No
## 8 0.0449 0.955 No No
## 9 0.424 0.576 Yes Yes
## 10 0.0187 0.981 No No
## # … with 2,103 more rowsbind_rows(
yardstick::accuracy(logistic_p_test_prob, Churn, .pred_class, event_level = "second"),
yardstick::precision(logistic_p_test_prob, Churn, .pred_class, event_level = "second"),
yardstick::recall(logistic_p_test_prob, Churn, .pred_class, event_level = "second"),
yardstick::specificity(logistic_p_test_prob, Churn, .pred_class, event_level = "second"),
yardstick::f_meas(logistic_p_test_prob, Churn, .pred_class, event_level = "second")
)## # A tibble: 5 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 accuracy binary 0.769
## 2 precision binary 0.548
## 3 recall binary 0.783
## 4 spec binary 0.764
## 5 f_meas binary 0.645Para poder determinar cual es el mejor punto de corte, es indispensable conocer el comportamiento y efecto de los diferentes puntos de corte.
Veamos un ejemplo visual en nuestra aplicación de Shiny: ConfusionMatrixShiny
5.4 Regularización
En muchas técnicas de aprendizaje automático, el aprendizaje consiste en encontrar los coeficientes que minimizan una función de costo. Un modelo estándar de mínimos cuadrados tiende a tener alguna variación, es decir, este modelo no se generalizará bien para un conjunto de datos diferente a sus datos de entrenamiento.
La regularización consiste en añadir una penalización a la función de costo. Esta penalización produce modelos más simples que generalizan mejor y evita el riesgo de sobreajuste.
El procedimiento de ajuste implica una función de pérdida, conocida como suma de cuadrados residual o RSS. Los coeficientes \(\beta\) se eligen de manera que minimicen esta función de pérdida.
\[RSS = \sum_{i=1}^n\left(y_i - \beta_0- \sum_{i=1}^p \beta_jx_{ij}\right)^2\]
Esto ajustará los coeficientes en función de sus datos de entrenamiento. Si hay ruido en los datos de entrenamiento, los coeficientes estimados no se generalizarán bien a los datos futuros. Aquí es donde entra la regularización y reduce o regulariza estas estimaciones aprendidas hacia cero.
En esta sección se verán las regularizaciones más usadas en machine learning:
- Ridge (conocida también como L2)
- Lasso (también conocida como L1)
- ElasticNet que combina tanto Lasso como Ridge.
Para cada una de estas regularizaciones ajustaremos un modelo de regresión lineal al conjunto de datos de viviendas de Ames con ayuda del paquete de tidymodels llamado parsnip.
5.4.1 Regularización Ridge
En este tipo de regularización RSS se modifica agregando una cantidad de contracción a los coeficientes, los cuales se estiman minimizando esta función. \(\lambda\) es el parámetro de ajuste que decide cuánto queremos penalizar la flexibilidad de el modelo.
\[\sum_{i=1}^n\left(y_i - \beta_0- \sum_{i=1}^p \beta_jx_{ij}\right)^2 + \lambda \sum_{j=1}^p \beta_j^2 = RSS + \lambda \sum_{j=1}^p \beta_j^2\]
El aumento de la flexibilidad de un modelo está representado por el aumento de sus coeficientes, si se desea minimizar la función anterior, los coeficientes deben ser pequeños.
Así es como la técnica de regresión de Ridge evita que los coeficientes aumenten demasiado. Además, reduce la asociación estimada de cada variable con la respuesta excepto la intersección \(\beta_0\). Esta intersección es una medida del valor medio de la respuesta cuando \(x_{i1} = x_{i2} =\dots= x_{ip} = 0\).
Cuando \(\lambda = 0\), el término de penalización no tiene efecto y las estimaciones serán iguales a mínimos cuadrados.
A medida que \(\lambda \rightarrow \infty\), el impacto de la penalización por contracción aumenta, y las estimaciones se acercarán a cero.
La selección de un buen valor de \(\lambda\) es fundamental. Las estimaciones de coeficientes producidas por este método también se conocen como la norma L2.
Nota: Es necesario estandarizar los predictores o llevarlos a la misma escala antes de aplicar esta regularización.
5.4.2 Regularización Lasso
Lasso es otra variación, en la que se minimiza la función RSS. Utiliza \(|\beta_j|\) en lugar de los cuadrados de \(\beta\) como penalización. Las estimaciones de coeficientes producidas por este método también se conocen como la norma L1.
\[\sum_{i=1}^n\left(y_i - \beta_0- \sum_{i=1}^p \beta_jx_{ij}\right)^2 + \lambda \sum_{j=1}^p |\beta_j| = RSS + \lambda \sum_{j=1}^p |\beta_j|\]
Cuando \(\lambda = 0\), el término de penalización no tiene efecto y las estimaciones serán iguales a mínimos cuadrados.
A medida que \(\lambda \rightarrow \infty\), el impacto de la penalización por contracción aumenta, y las estimaciones se convierten en cero (eliminando variables).
Este método de regularizacion permite eliminar coeficientes con alta variación, lo cual ayuda a la selección de variables.
5.4.3 Comparación entre Ridge y Lasso
La regresión Ridge se puede considerar como la solución de una ecuación, donde la suma de los cuadrados de los coeficientes es menor o igual que \(s\), donde \(s\) es una constante que existe para cada valor del factor de contracción \(\lambda\)
\[\beta_1^2 + \beta_2^2 \leq s\]
Esto implica que los coeficientes de la regresión Ridge tienen el RSS (función de pérdida) más pequeño para todos los puntos que se encuentran dentro del círculo dado por la función de restricción \(\beta_1^2 + \beta_2^2 \leq s\).
Y en la regresión Lasso se puede considerar como una ecuación en la que la suma del módulo de coeficientes es menor o igual que \(s\).
\[|\beta_1| + |\beta_2| \leq s\]
Esto implica que los coeficientes de lasso tienen la RSS (función de pérdida) más pequeña para todos los puntos que se encuentran dentro del diamante dado por la función de restricción \(|\beta_1| + |\beta_2| \leq s\)
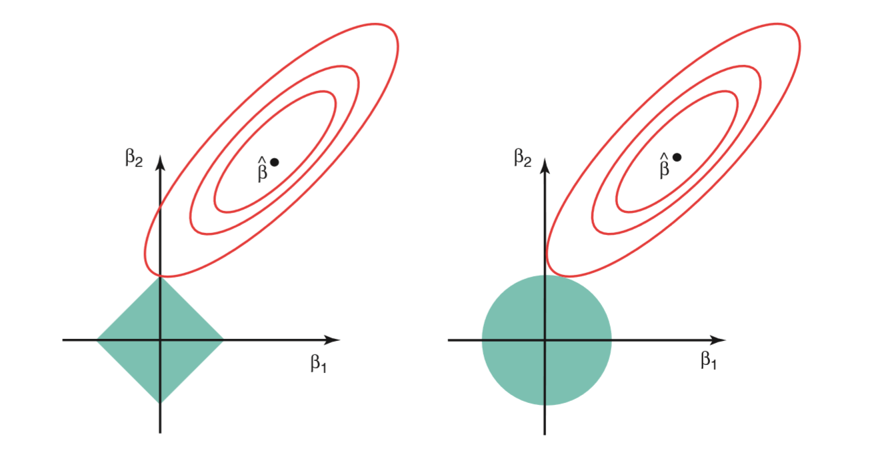
La imagen de arriba muestra las funciones de restricción (áreas verdes) para Lasso (izquierda) y Ridge (derecha), junto con contornos para RSS (elipse roja).
Para un valor muy grande de \(s\), las regiones verdes contendrán el centro de la elipse, lo que hará que las estimaciones de los coeficientes de ambas técnicas de regresión sean iguales a las estimaciones de mínimos cuadrados. Pero este no es el caso en la imagen de arriba.
En este caso, las estimaciones del coeficiente de regresión de Lasso y Ridge vienen dadas por el primer punto en el que una elipse contacta con la región de restricción. Dado que la regresión Ridge tiene una restricción circular sin puntos agudos, esta intersección generalmente no ocurrirá en un eje, por lo que las estimaciones del coeficiente de regresión de Ridge serán exclusivamente distintas de cero.
Sin embargo, la restricción de Lasso tiene esquinas en cada uno de los ejes, por lo que la elipse a menudo intersectará la región de restricción en un eje. Cuando esto ocurre, uno de los coeficientes será igual a cero. En dimensiones más altas, muchas de las estimaciones de coeficientes pueden ser guales a cero simultáneamente.
Desventajas
Regresión Ridge: Reducirá los coeficientes de los predictores menos importantes, muy cerca de cero. Pero nunca los hará exactamente cero. En otras palabras, el modelo final incluirá todos los predictores.
Regresión Lasso: La penalización L1 tiene el efecto de forzar algunas de las estimaciones de coeficientes a ser exactamente iguales a cero cuando el parámetro de ajuste \(\lambda\) es suficientemente grande. Por lo tanto, este método realiza una selección de variables.
5.4.4 ElasticNet
ElasticNet surgió por primera vez como resultado de la crítica a Lasso, cuya selección de variables puede ser demasiado dependiente de los datos y, por lo tanto, inestable. La solución es combinar las penalizaciones de la regresión de Ridge y Lasso para obtener lo mejor de ambas regularizaciones.
ElasticNet tiene como objetivo minimizar la siguiente función de pérdida:
\[\frac{\sum_{i=1}^n\left(y_i - \beta_0- \sum_{i=1}^p \beta_jx_{ij}\right)^2}{2n} + \lambda\left( ({1-\alpha}) \sum_{j=1}^p|\beta_j| + \alpha \sum_{j=1}^p \beta_j ^2\right)\]
\[= \frac{RSS}{2n}+ \lambda\left( ({1-\alpha}) \sum_{j=1}^p|\beta_j| + \alpha \sum_{j=1}^p \beta_j ^2\right)\]
donde \(\alpha \in [0,1]\) es el parámetro de mezcla entre la regularización Ridge \((\alpha = 0)\) y la regularización Lasso \((\alpha = 1)\).
La combinación de ambas penalizaciones suele dar lugar a buenos resultados. Una estrategia frecuentemente utilizada es asignarle casi todo el peso a la penalización L1 ( \(\alpha \approx 1\)) para conseguir seleccionar predictores y menos peso a la regularización \(L2\) para dar cierta estabilidad en el caso de que algunos predictores estén correlacionados.

5.4.5 ElasticNet para regresión lineal
Utilizando el modelo linear_reg() del paquete parsnip. Hay varios mecanismos que pueden realizar la regularización/penalización, los paquetes glmnet, sparklyr, keras o stan.
Usemos el primero aquí. El paquete glmnet solo implementa un método que no es de fórmula, pero parsnip permitirá que se use cualquiera de ellos.
Cuando se utiliza la regularización, los predictores deben de centrarse y escalarse primero antes de pasar al modelo. El método de la fórmula no lo hará automáticamente, por lo que tendremos que hacerlo nosotros mismos como se hizo en la sección 4.6 Preparación de conjunto de datos con la receta receta_casas.
En R existen dos parámetros que nos permiten hacer la regularización:
penalty: Es un número no negativo que representa la cantidad total de regularización (solo glmnet, keras y spark).mixture: Es un número entre cero y uno (inclusivo) que es la proporción de regularización L1 en el modelo. Cuandomixture = 1, es un modelo de Lasso puro, mientras quemixture = 0indica que se está utilizando un modelo Ridge.
library(parallel)
library(doParallel)
#Partición
set.seed(4595)
ames_split <- initial_split(ames, prop = 0.75)
ames_train <- training(ames_split)
ames_test <- testing(ames_split)
set.seed(2453)
ames_folds<- vfold_cv(ames_train)
# Receta
receta_casas <- recipe(Sale_Price ~ . , data = ames_train) %>%
step_log(Sale_Price, skip = T) %>%
step_unknown(Alley) %>%
step_rename(Year_Remod = Year_Remod_Add) %>%
step_rename(ThirdSsn_Porch = Three_season_porch) %>%
step_ratio(Bedroom_AbvGr, denom = denom_vars(Gr_Liv_Area)) %>%
step_mutate(
Age_House = Year_Sold - Year_Remod,
TotalSF = Gr_Liv_Area + Total_Bsmt_SF,
AvgRoomSF = Gr_Liv_Area / TotRms_AbvGrd,
Pool = if_else(Pool_Area > 0, 1, 0),
Exter_Cond = forcats::fct_collapse(Exter_Cond, Good = c("Typical", "Good", "Excellent"))) %>%
step_relevel(Exter_Cond, ref_level = "Good") %>%
step_normalize(all_predictors(), -all_nominal()) %>%
step_dummy(all_nominal()) %>%
step_interact(~ Second_Flr_SF:First_Flr_SF) %>%
step_interact(~ matches("Bsmt_Cond"):TotRms_AbvGrd) %>%
step_rm(
First_Flr_SF, Second_Flr_SF, Year_Remod,
Bsmt_Full_Bath, Bsmt_Half_Bath,
Kitchen_AbvGr, BsmtFin_Type_1_Unf,
Total_Bsmt_SF, Kitchen_AbvGr, Pool_Area,
Gr_Liv_Area, Sale_Type_Oth, Sale_Type_VWD
) %>%
prep()
# Declaración del modelo
lasso_ridge_regression_model <- linear_reg(
mixture = tune(),
penalty = tune()) %>%
set_mode("regression") %>%
set_engine("glmnet")
# Declaración del flujo de trabajo
lasso_ridge_regression_workflow <- workflow() %>%
add_model(lasso_ridge_regression_model) %>%
add_recipe(receta_casas)
# Parámetros a probar
lasso_ridge_regression_parameters_set <- parameters(
penalty(range = c(-8, 1), trans = log10_trans()),
mixture(range = c(0,1))
)
# Grid
lasso_ridge_regression_parameters_grid <- grid_regular(
lasso_ridge_regression_parameters_set, levels = c(40, 20)
)
ctrl_grid <- control_grid(save_pred = T, verbose = T)UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
lasso_ridge_regression_tunning <- tune_grid(
lasso_ridge_regression_workflow,
resamples = ames_folds,
grid = lasso_ridge_regression_parameters_grid,
metrics = metric_set(rmse, rsq, mae, mape),
control = ctrl_grid
)
stopCluster(cluster)
# Se guarda tune_grid en RDS
lasso_ridge_regression_tunning %>%
saveRDS("models/lasso_ridge_regression_tunning.rds")lasso_ridge_regression_tunning <- readRDS("models/lasso_ridge_regression_tunning.rds")
lasso_ridge_regression_tunning## # Tuning results
## # 10-fold cross-validation
## # A tibble: 10 × 5
## splits id .metrics .notes .predictions
## <list> <chr> <list> <list> <list>
## 1 <split [1977/220]> Fold01 <tibble [3,200 × 6]> <tibble [1 × 1]> <tibble>
## 2 <split [1977/220]> Fold02 <tibble [3,200 × 6]> <tibble [1 × 1]> <tibble>
## 3 <split [1977/220]> Fold03 <tibble [3,200 × 6]> <tibble [1 × 1]> <tibble>
## 4 <split [1977/220]> Fold04 <tibble [3,200 × 6]> <tibble [1 × 1]> <tibble>
## 5 <split [1977/220]> Fold05 <tibble [3,200 × 6]> <tibble [1 × 1]> <tibble>
## 6 <split [1977/220]> Fold06 <tibble [3,200 × 6]> <tibble [1 × 1]> <tibble>
## 7 <split [1977/220]> Fold07 <tibble [3,200 × 6]> <tibble [1 × 1]> <tibble>
## 8 <split [1978/219]> Fold08 <tibble [3,200 × 6]> <tibble [1 × 1]> <tibble>
## 9 <split [1978/219]> Fold09 <tibble [3,200 × 6]> <tibble [1 × 1]> <tibble>
## 10 <split [1978/219]> Fold10 <tibble [3,200 × 6]> <tibble [1 × 1]> <tibble># Métrica R cuadrada
lasso_ridge_regression_tunning %>%
unnest(.metrics) %>%
filter(.metric == "rsq") %>%
arrange(desc(.estimate)) %>%
head(10)## # A tibble: 10 × 10
## splits id penalty mixture .metric .estimator .estimate .config
## <list> <chr> <dbl> <dbl> <chr> <chr> <dbl> <chr>
## 1 <split [1977/220]> Fold… 1 e-4 0.0526 rsq standard 0.734 Prepro…
## 2 <split [1977/220]> Fold… 1.34e-4 0.0526 rsq standard 0.734 Prepro…
## 3 <split [1977/220]> Fold… 1.80e-4 0.0526 rsq standard 0.734 Prepro…
## 4 <split [1977/220]> Fold… 2.42e-4 0.0526 rsq standard 0.734 Prepro…
## 5 <split [1977/220]> Fold… 3.26e-4 0.0526 rsq standard 0.734 Prepro…
## 6 <split [1977/220]> Fold… 4.38e-4 0.0526 rsq standard 0.734 Prepro…
## 7 <split [1977/220]> Fold… 5.88e-4 0.0526 rsq standard 0.734 Prepro…
## 8 <split [1977/220]> Fold… 7.90e-4 0.0526 rsq standard 0.734 Prepro…
## 9 <split [1977/220]> Fold… 1.06e-3 0.0526 rsq standard 0.734 Prepro…
## 10 <split [1977/220]> Fold… 1.43e-3 0.0526 rsq standard 0.734 Prepro…
## # … with 2 more variables: .notes <list>, .predictions <list># Analizando las métricas de manera visual
graf_rsq <- lasso_ridge_regression_tunning %>%
unnest(.metrics) %>%
filter(.metric == "rsq") %>%
ggplot(aes(x = penalty, y = .estimate)) +
scale_x_log10() +
geom_line(aes(color = id))+
theme_minimal()+
ggtitle('R cuadrada vs Penalización')
graf_rsq## Warning: Removed 190 row(s) containing missing values (geom_path).
lasso_ridge_regression_tunning %>% collect_metrics()## # A tibble: 3,200 × 8
## penalty mixture .metric .estimator mean n std_err .config
## <dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 0.0001 0 mae standard 180544. 10 1014. Preprocess…
## 2 0.0001 0 mape standard 100. 10 0.0000689 Preprocess…
## 3 0.0001 0 rmse standard 197259. 10 1734. Preprocess…
## 4 0.0001 0 rsq standard 0.687 10 0.0110 Preprocess…
## 5 0.000134 0 mae standard 180544. 10 1014. Preprocess…
## 6 0.000134 0 mape standard 100. 10 0.0000689 Preprocess…
## 7 0.000134 0 rmse standard 197259. 10 1734. Preprocess…
## 8 0.000134 0 rsq standard 0.687 10 0.0110 Preprocess…
## 9 0.000180 0 mae standard 180544. 10 1014. Preprocess…
## 10 0.000180 0 mape standard 100. 10 0.0000689 Preprocess…
## # … with 3,190 more rowslasso_ridge_regression_tunning %>%
collect_metrics() %>%
filter(mixture == 0) %>%
ggplot(aes(penalty, mean, color = .metric)) +
geom_errorbar(aes(
ymin = mean - std_err,
ymax = mean + std_err), alpha = 0.5) +
geom_line(size = 0.8) +
facet_wrap(~.metric, scales = "free", nrow = 2) +
scale_x_log10() +
theme(legend.position = "none")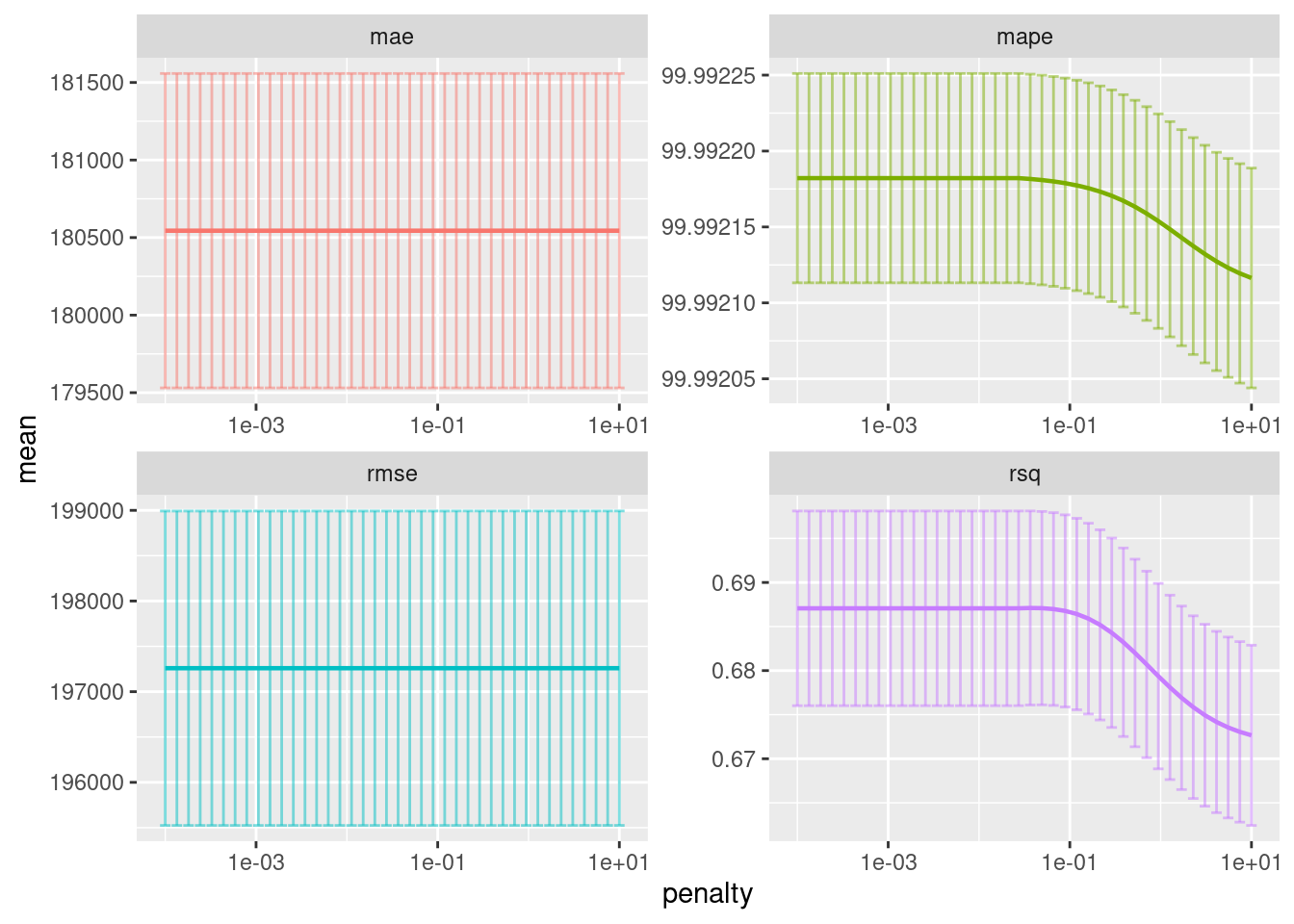
autoplot(lasso_ridge_regression_tunning)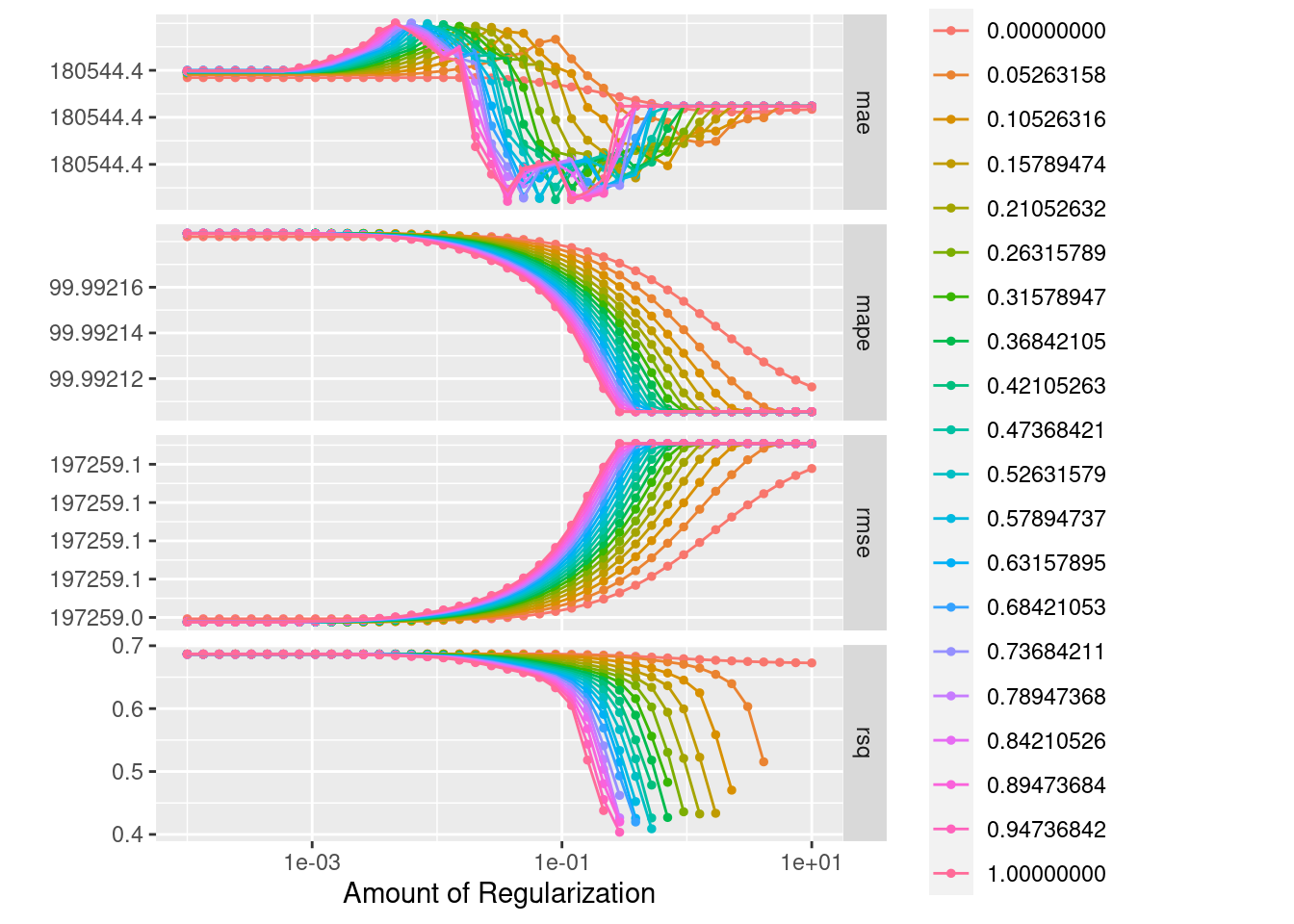
# Selección de los mejores 10 modelos según la métrica R cuadrada
lasso_ridge_regression_tunning %>%
show_best(n = 10, metric = "rsq")## # A tibble: 10 × 8
## penalty mixture .metric .estimator mean n std_err .config
## <dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 0.0367 0 rsq standard 0.687 10 0.0110 Preprocessor1_Model0…
## 2 0.0492 0 rsq standard 0.687 10 0.0110 Preprocessor1_Model0…
## 3 0.0273 0 rsq standard 0.687 10 0.0110 Preprocessor1_Model0…
## 4 0.0001 0 rsq standard 0.687 10 0.0110 Preprocessor1_Model0…
## 5 0.000134 0 rsq standard 0.687 10 0.0110 Preprocessor1_Model0…
## 6 0.000180 0 rsq standard 0.687 10 0.0110 Preprocessor1_Model0…
## 7 0.000242 0 rsq standard 0.687 10 0.0110 Preprocessor1_Model0…
## 8 0.000326 0 rsq standard 0.687 10 0.0110 Preprocessor1_Model0…
## 9 0.000438 0 rsq standard 0.687 10 0.0110 Preprocessor1_Model0…
## 10 0.000588 0 rsq standard 0.687 10 0.0110 Preprocessor1_Model0…# Selección del mejor modelo según la métrica R cuadrada
lasso_ridge_regression_best_model <- select_best(
lasso_ridge_regression_tunning, metric = "rsq")
lasso_ridge_regression_best_model## # A tibble: 1 × 3
## penalty mixture .config
## <dbl> <dbl> <chr>
## 1 0.0367 0 Preprocessor1_Model021# Selección del mejor modelo por un error estándar
lasso_ridge_regression_best_1se_model <- select_by_one_std_err(
lasso_ridge_regression_tunning, metric = "rsq", "rsq")
lasso_ridge_regression_best_1se_model## # A tibble: 1 × 10
## penalty mixture .metric .estimator mean n std_err .config .best .bound
## <dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr> <dbl> <dbl>
## 1 0.0001 0 rsq standard 0.687 10 0.0110 Preproces… 0.687 0.676# Selección del mejor modelo por porcentaje de pérdida
lasso_ridge_regression_best_pct_loss_model <- select_by_pct_loss(
lasso_ridge_regression_tunning, metric = "rsq", "rsq", limit = 5)
lasso_ridge_regression_best_pct_loss_model## # A tibble: 1 × 10
## penalty mixture .metric .estimator mean n std_err .config .best .loss
## <dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr> <dbl> <dbl>
## 1 0.0001 0 rsq standard 0.687 10 0.0110 Preproce… 0.687 0.00578# Modelo final
lasso_ridge_regression_final_model <- lasso_ridge_regression_workflow %>%
finalize_workflow(lasso_ridge_regression_best_1se_model) %>%
parsnip::fit(data = ames_train)
lasso_ridge_regression_final_model %>%
tidy() %>% as.data.frame() %>%
arrange(desc(abs(estimate))) %>%
head(20)## term estimate penalty
## 1 (Intercept) 12.02013159 1e-04
## 2 Year_Built 0.10133358 1e-04
## 3 TotRms_AbvGrd 0.07467521 1e-04
## 4 Fireplaces 0.06871314 1e-04
## 5 Garage_Area 0.05345236 1e-04
## 6 Full_Bath 0.05180514 1e-04
## 7 Garage_Cars 0.04578311 1e-04
## 8 BsmtFin_SF_1 -0.04297080 1e-04
## 9 Mas_Vnr_Area 0.03498704 1e-04
## 10 Bsmt_Unf_SF 0.03260094 1e-04
## 11 Wood_Deck_SF 0.02892588 1e-04
## 12 Screen_Porch 0.02266798 1e-04
## 13 Open_Porch_SF 0.02162425 1e-04
## 14 Lot_Area 0.02144120 1e-04
## 15 Enclosed_Porch 0.02071560 1e-04
## 16 Latitude 0.01936046 1e-04
## 17 Longitude -0.01905589 1e-04
## 18 Half_Bath 0.01890797 1e-04
## 19 Misc_Val -0.01608877 1e-04
## 20 Bedroom_AbvGr -0.01417964 1e-04# Predicciones
results <- predict(lasso_ridge_regression_final_model, ames_test) %>%
dplyr::bind_cols(truth = ames_test$Sale_Price) %>%
mutate(.pred = exp(.pred)) %>%
dplyr::rename(pred_laso_ridge_reg = .pred, Sale_Price = truth)
head(results)## # A tibble: 6 × 2
## pred_laso_ridge_reg Sale_Price
## <dbl> <int>
## 1 131177. 105000
## 2 177281. 185000
## 3 191728. 180400
## 4 122011. 141000
## 5 242145. 210000
## 6 188283. 216000results %>% yardstick::metrics(Sale_Price, pred_laso_ridge_reg)## # A tibble: 3 × 3
## .metric .estimator .estimate
## <chr> <chr> <dbl>
## 1 rmse standard 40274.
## 2 rsq standard 0.759
## 3 mae standard 27272.results %>%
ggplot(aes(x = pred_laso_ridge_reg, y = Sale_Price)) +
geom_point() +
geom_abline(color = "red") +
xlab("Prediction") +
ylab("Observation") +
ggtitle("Comparisson")
5.4.6 ElasticNet para regresión logística
tilizando el modelo logistic_reg() del paquete parsnip. Hay varios mecanismos que pueden realizar la regularización/penalización, los paquetes glmnet, sparklyr, keras o stan.
Usemos el primero aquí. El paquete glmnet solo implementa un método que no es de fórmula, pero parsnip permitirá que se use cualquiera de ellos.
Cuando se utiliza la regularización, los predictores deben de centrarse y escalarse primero antes de pasar al modelo. El método de la fórmula no lo hará automáticamente, por lo que tendremos que hacerlo nosotros mismos como se hizo en la sección 4.6 Preparación de conjunto de datos con la receta receta_casas.
En R existen dos parámetros que nos permiten hacer la regularización:
penalty: Es un número no negativo que representa la cantidad total de regularización (solo glmnet, keras y spark).mixture: Es un número entre cero y uno (inclusivo) que es la proporción de regularización L1 en el modelo. Cuandomixture = 1, es un modelo de Lasso puro, mientras quemixture = 0indica que se está utilizando un modelo Ridge.
# Lectura de datos
telco <- read_csv("data/Churn.csv")##
## ── Column specification ────────────────────────────────────────────────────────
## cols(
## .default = col_character(),
## SeniorCitizen = col_double(),
## tenure = col_double(),
## MonthlyCharges = col_double(),
## TotalCharges = col_double()
## )
## ℹ Use `spec()` for the full column specifications.# Partición de muestras
set.seed(1234)
telco_split <- initial_split(telco, prop = .7)
telco_train <- training(telco_split)
telco_test <- testing(telco_split)
set.seed(1234)
telco_folds <- vfold_cv(telco_train)
# Receta
binner <- function(x) {
cut(x, breaks = c(0, 12, 24, 36,48,60,72), include.lowest = TRUE) %>%
as.numeric()
}
telco_rec <- recipe(Churn ~ ., data = telco_train) %>%
update_role(customerID, new_role = "id variable") %>%
step_num2factor(tenure, transform = binner,
levels = c("0-1 year", "1-2 years", "2-3 years", "3-4 years", "4-5 years", "5-6 years")) %>%
step_normalize(all_numeric_predictors()) %>%
step_dummy(all_nominal_predictors()) %>%
step_impute_median(all_numeric_predictors()) %>%
step_rm(customerID, skip=T) %>%
prep()
# Declaración del modelo de regresión logística
regularized_logistic_model <- logistic_reg(
mixture = tune(), penalty = tune()) %>%
set_mode('classification') %>%
set_engine("glmnet")
# Declaración del workflow
regularized_logistic_workflow <- workflow() %>%
add_recipe(telco_rec) %>%
add_model(regularized_logistic_model)
# Fijación de parámetros
regularized_parameters_set <- parameters(
penalty(
range = c(-10, 2),
trans = log10_trans()
),
dials::mixture()
)
# Declaración del grid
regularized_parameters_grid <- grid_regular(
regularized_parameters_set, levels = c(15, 15)
)
ctrl_grid <- control_grid(save_pred = T, verbose = T)# Se crea el cluster de trabajo
UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
regularized_tune_result <- tune_grid(
regularized_logistic_workflow,
resamples = telco_folds,
grid = regularized_parameters_grid,
metrics = metric_set(roc_auc, pr_auc),
control = ctrl_grid
)
# Se detiene el cluster de trabajo
stopCluster(cluster)
# Se guarda tune_grid en formato RDS
regularized_tune_result %>%
saveRDS("models/regularized_logistic_regression.rds")# Se carga el modelo
regularized_tune_result <- readRDS("models/regularized_logistic_regression.rds")
# Métricas
regularized_tune_result %>% unnest(.metrics)## # A tibble: 4,500 × 10
## splits id penalty mixture .metric .estimator .estimate
## <list> <chr> <dbl> <dbl> <chr> <chr> <dbl>
## 1 <split [4437/493]> Fold01 1 e-10 0 roc_auc binary 0.777
## 2 <split [4437/493]> Fold01 7.20e-10 0 roc_auc binary 0.777
## 3 <split [4437/493]> Fold01 5.18e- 9 0 roc_auc binary 0.777
## 4 <split [4437/493]> Fold01 3.73e- 8 0 roc_auc binary 0.777
## 5 <split [4437/493]> Fold01 2.68e- 7 0 roc_auc binary 0.777
## 6 <split [4437/493]> Fold01 1.93e- 6 0 roc_auc binary 0.777
## 7 <split [4437/493]> Fold01 1.39e- 5 0 roc_auc binary 0.777
## 8 <split [4437/493]> Fold01 1 e- 4 0 roc_auc binary 0.777
## 9 <split [4437/493]> Fold01 7.20e- 4 0 roc_auc binary 0.777
## 10 <split [4437/493]> Fold01 5.18e- 3 0 roc_auc binary 0.777
## # … with 4,490 more rows, and 3 more variables: .config <chr>, .notes <list>,
## # .predictions <list># Analizando las métricas de manera visual
graf_prec <- regularized_tune_result %>%
unnest(.metrics) %>%
filter(.metric == "pr_auc") %>%
ggplot(aes(x = penalty, y = .estimate)) +
scale_x_log10() +
geom_line(aes(color = id))+
theme_minimal()+
ggtitle('Precisión: Penalización vs. PR AUC')
graf_prec
graf_roc <- regularized_tune_result %>%
unnest(.metrics) %>%
filter(.metric == "roc_auc") %>%
ggplot(aes(x = penalty, y = .estimate)) +
scale_x_log10() +
geom_line(aes(color = id))+
theme_minimal()+
ggtitle('AUC: Penalización vs. ROC AUC')
graf_roc
regularized_tune_result %>%
collect_metrics() %>%
filter(mixture == 0.5) %>%
ggplot(aes(penalty, mean, color = .metric)) +
geom_errorbar(
aes(ymin = mean - std_err, ymax = mean + std_err),
alpha = 0.5
) +
geom_line(size = 0.8) +
facet_wrap(~.metric, scales = "free", nrow = 2) +
scale_x_log10() +
theme(legend.position = "none")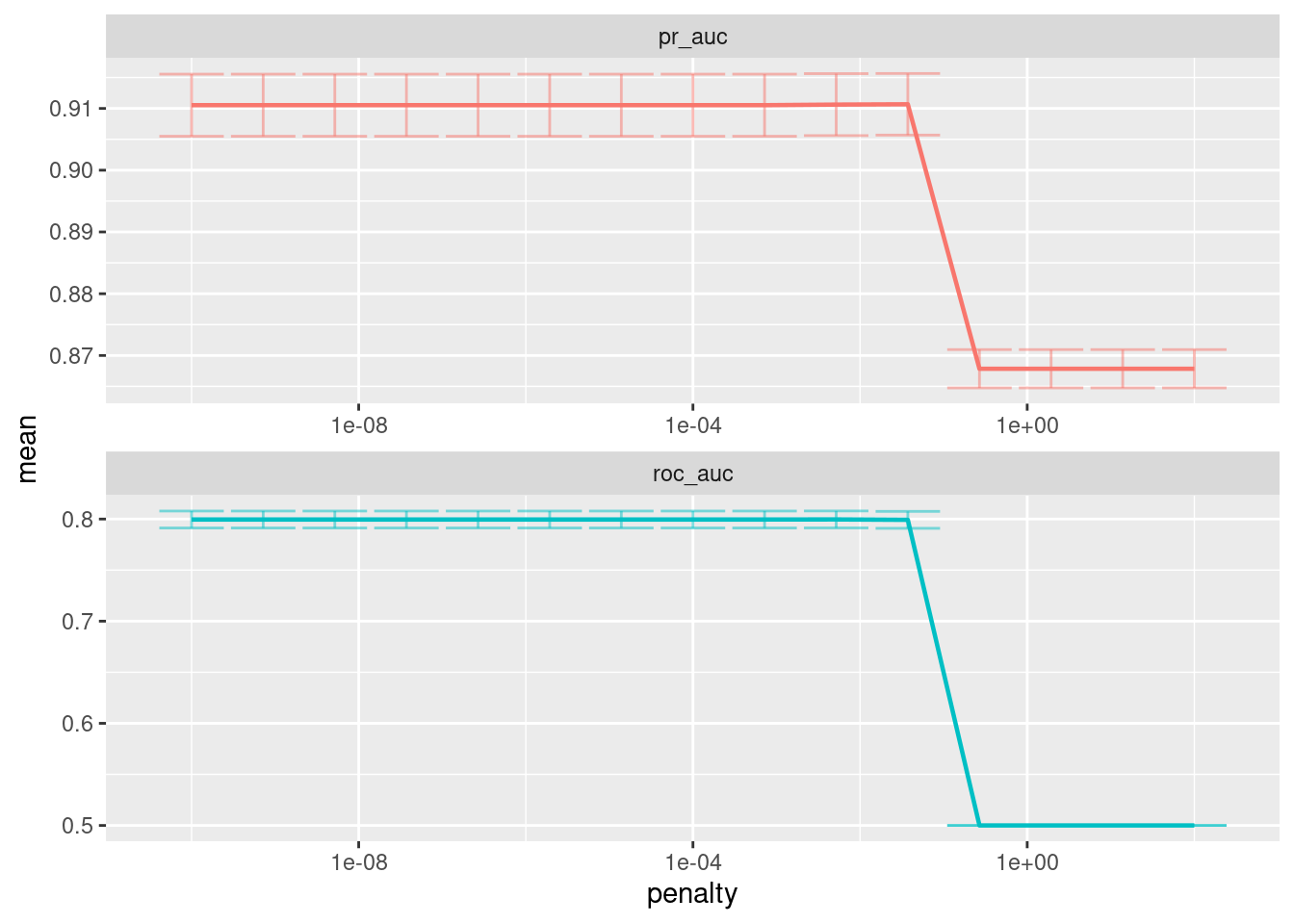
autoplot(regularized_tune_result)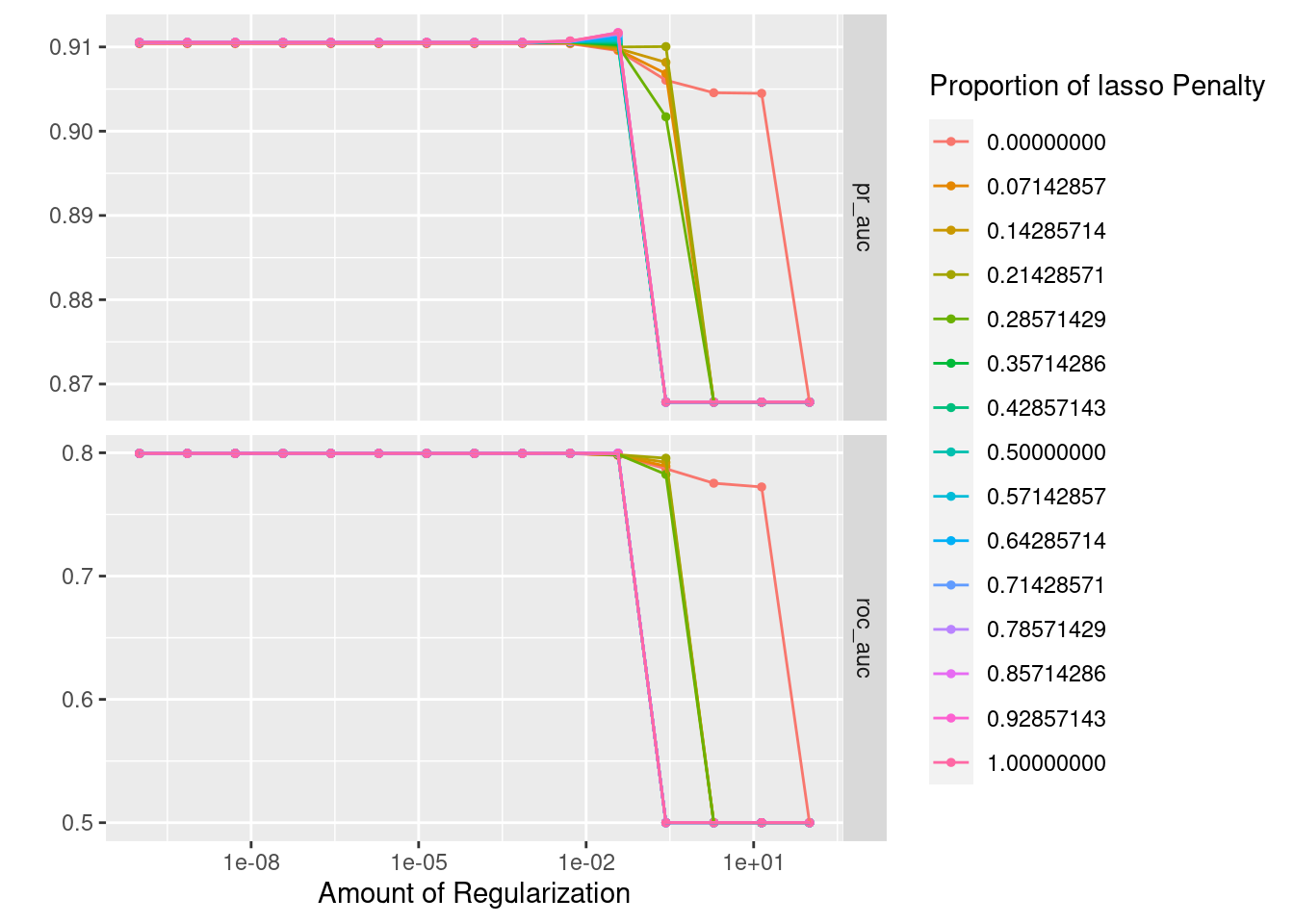
regularized_tune_result %>% collect_metrics() %>%
group_by(.metric) %>%
summarise(
max = max(mean),
min = min(mean),
mean = mean(mean),
median = median(mean),
.groups = "drop"
)## # A tibble: 2 × 5
## .metric max min mean median
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 pr_auc 0.912 0.868 0.900 0.900
## 2 roc_auc 0.800 0.5 0.728 0.728# Mejores 10 resultados para la métrica de precisión
show_best(regularized_tune_result, n = 10, metric = "pr_auc")## # A tibble: 10 × 8
## penalty mixture .metric .estimator mean n std_err .config
## <dbl> <dbl> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 0.0373 0.929 pr_auc binary 0.912 10 0.00492 Preprocessor1_Model206
## 2 0.0373 0.857 pr_auc binary 0.912 10 0.00494 Preprocessor1_Model191
## 3 0.0373 1 pr_auc binary 0.912 10 0.00493 Preprocessor1_Model221
## 4 0.0373 0.786 pr_auc binary 0.912 10 0.00496 Preprocessor1_Model176
## 5 0.0373 0.714 pr_auc binary 0.911 10 0.00497 Preprocessor1_Model161
## 6 0.0373 0.643 pr_auc binary 0.911 10 0.00497 Preprocessor1_Model146
## 7 0.0373 0.571 pr_auc binary 0.911 10 0.00498 Preprocessor1_Model131
## 8 0.00518 1 pr_auc binary 0.911 10 0.00501 Preprocessor1_Model220
## 9 0.00518 0.857 pr_auc binary 0.911 10 0.00502 Preprocessor1_Model190
## 10 0.00518 0.929 pr_auc binary 0.911 10 0.00501 Preprocessor1_Model205# Selección del mejor modelo según la métrica de precisión
best_regularized_logistic_model <- select_best(regularized_tune_result, metric = "pr_auc")
# Selección del mejor modelo por un error estándar
best_regularized_logistic_model_1se <- select_by_one_std_err(
regularized_tune_result, metric = "pr_auc", "pr_auc")
# Modelo final
final_regularized_logistic_model <- regularized_logistic_workflow %>%
finalize_workflow(best_regularized_logistic_model_1se) %>%
parsnip::fit(data = telco_train)
final_regularized_logistic_model %>% tidy() ## # A tibble: 4 × 3
## term estimate penalty
## <chr> <dbl> <dbl>
## 1 (Intercept) -1.23 0.0000000001
## 2 SeniorCitizen 0.234 0.0000000001
## 3 MonthlyCharges 1.12 0.0000000001
## 4 TotalCharges -1.17 0.0000000001results <- predict(final_regularized_logistic_model, telco_test, type = 'prob') %>%
dplyr::bind_cols(truth =telco_test$Churn) %>%
mutate(truth = factor(truth, levels = c('No', 'Yes'), labels = c('No', 'Yes')))
head(results, 10)## # A tibble: 10 × 3
## .pred_No .pred_Yes truth
## <dbl> <dbl> <fct>
## 1 0.808 0.192 No
## 2 0.331 0.669 Yes
## 3 0.835 0.165 No
## 4 0.885 0.115 No
## 5 0.919 0.0812 No
## 6 0.548 0.452 No
## 7 0.875 0.125 No
## 8 0.869 0.131 No
## 9 0.813 0.187 Yes
## 10 0.925 0.0749 Nopr_curve_data <- pr_curve(
results,
truth = truth,
estimate = .pred_Yes,
event_level = 'second'
)
roc_curve_data <- roc_curve(
results,
truth = truth,
estimate = .pred_Yes,
event_level = 'second'
)pr_curve_plot <- pr_curve_data %>%
ggplot(aes(x = recall, y = precision)) +
geom_path(size = 1, colour = 'lightblue') +
coord_equal() +
ggtitle("Precision vs Recall")+
theme_minimal()
pr_curve_plot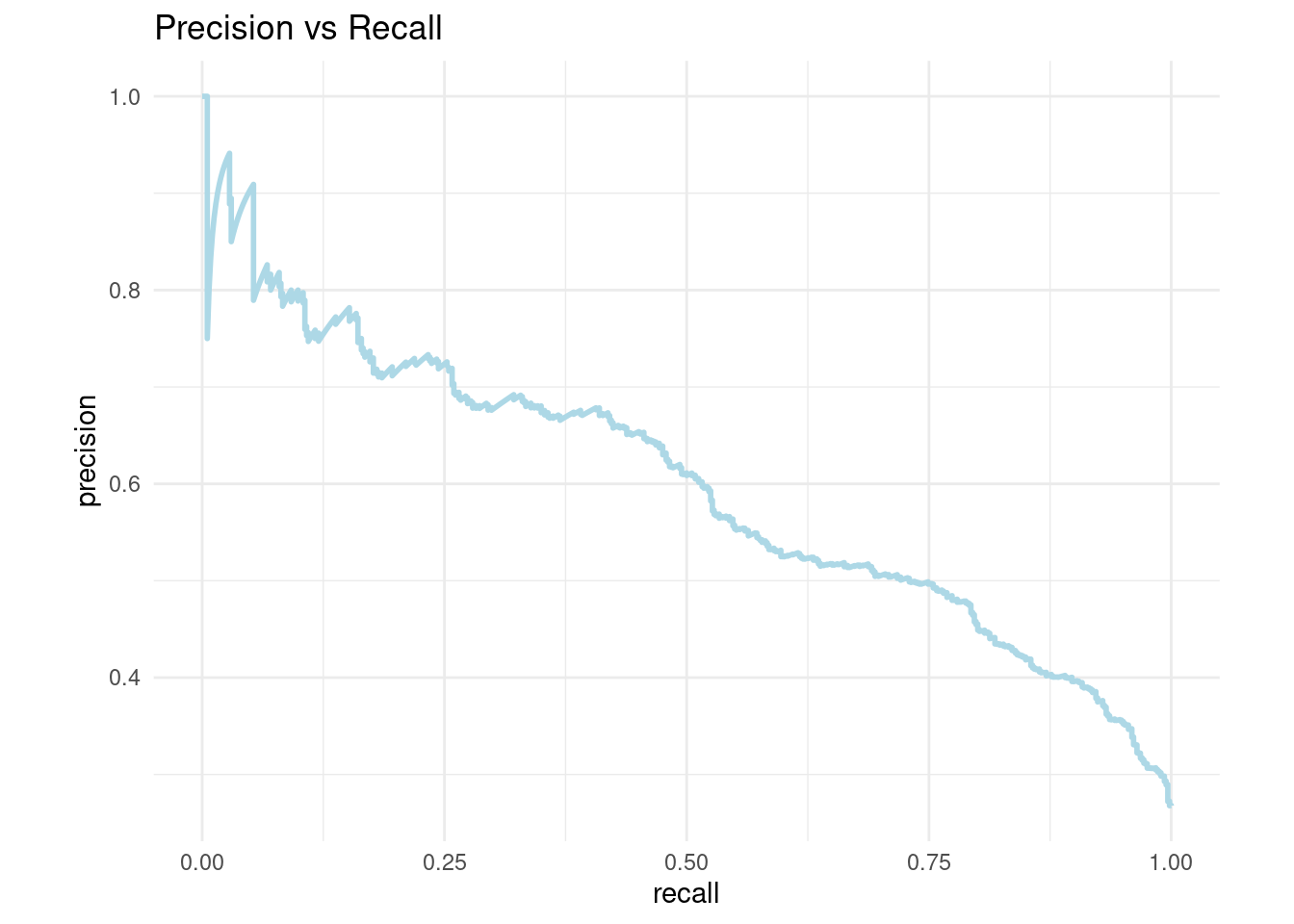
roc_curve_plot <- roc_curve_data %>%
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_path(size = 1, colour = 'lightblue') +
geom_abline() +
coord_equal() +
ggtitle("ROC Curve")+
theme_minimal()
roc_curve_plot
La curva Recall vs. Precision muestra la compensación entre precisión y recall para diferentes umbrales. Un área alta debajo de la curva representa tanto un alto recall como una alta precisión, donde la alta precisión se relaciona con una tasa baja de falsos positivos y recall alto se relaciona con una tasa baja de falsos negativos.
Por ejemplo, en caso de que queramos tener una sensibilidad al rededor de 0.75, inevitablemente se obtendrá una tasa de falsos positivos de 0.45.
Una curva ROC es un gráfico que muestra el rendimiento de un modelo de clasificación en todos los umbrales de clasificación. Esta curva traza dos parámetros:
Tasa de verdaderos positivos:
\[TPR=\frac{TP}{TP + FN}\]
Tasa de falsos positivos:
\[FPR = \frac{FP}{FP + TN}\]
Una curva ROC traza TPR frente a FPR en diferentes umbrales de clasificación. Si se reduce el umbral de clasificación, se clasifican más elementos como positivos, lo que aumenta tanto los falsos positivos como los verdaderos positivos.
Por ejemplo, si queremos tener una precisión de 0.80, la cobertura será apenas de 0.125 del total de positivos.
5.5 K-Nearest-Neighbor
KNN es un algoritmo de aprendizaje supervisado que podemos usar tanto para regresión como clasificación. Es un algoritmo fácil de interpretar y que permite ser flexible en el balance entre sesgo y varianza (dependiendo de los hiper-parámetros seleccionados).
El algoritmo de K vecinos más cercanos realiza comparaciones entre un nuevo elemento y las observaciones anteriores que ya cuentan con etiqueta. La esencia de este algoritmo está en etiquetar a un nuevo elemento de manera similar a como están etiquetados aquellos K elementos que más se le parecen. Veremos este proceso para cada uno de los posibles casos:
5.5.1 Clasificación
La idea detrás del algoritmo es sencilla, eletiqueta una nueva observación en la categoria que tenga mas elementos de las k observaciones más cercanas, es decir:
Seleccionamos el hiper-parámetro K como el número elegido de vecinos.
Se calculará la similitud (distancia) de esta nueva observación a cada observación existente.
Ordenaremos estas distancias de menor a mayor.
Tomamos las K primeras entradas de la lista ordenada.
La nueva observación será asignada al grupo que tenga mayor número de observaciones en estas k primeras distancias (asignación por moda)
A continuación se ejemplifica este proceso:
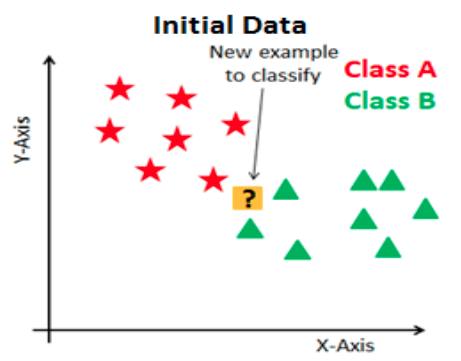
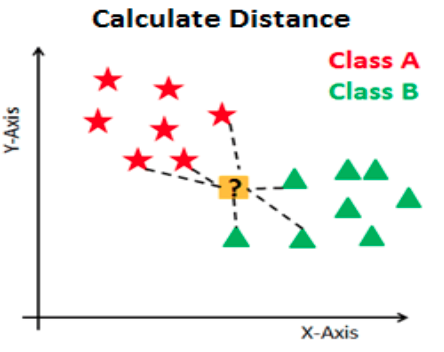
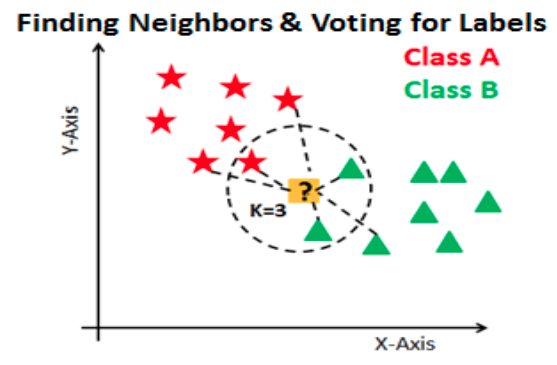
Ejemplo:
Otro método que permite tener mayor control sobre las clasificaciones es asignar la probabilidad de pertenencia a cada clase de acuerdo con la proporción existente de cada una de las mismas. A partir de dichas probabilidades, el usuario puede determinar el punto de corte que sea más conveniente para el problema a resolver.
5.5.2 Regresión
En el caso de regresión, la eletiqueta de una nueva observación se realiza a través del promedio del valor en las k observaciones más cercanas, es decir:
Seleccionamos el hiper-parámetro K como el número elegido de vecinos.
Se calculará la similitud (distancia) de esta nueva observación a cada observación existente
Ordenaremos estas distancias de menor a mayor
Tomamos las K primeras entradas de la lista ordenada.
La nueva observación será etiquetada mediante el promedio del valor de las observaciones en estas k primeras distancias.
Considerando un modelo de 3 vecinos más cercanos, las siguientes imágenes muestran el proceso de ajuste y predicción de nuevas observaciones.
Ejemplo de balance de sesgo y varianza
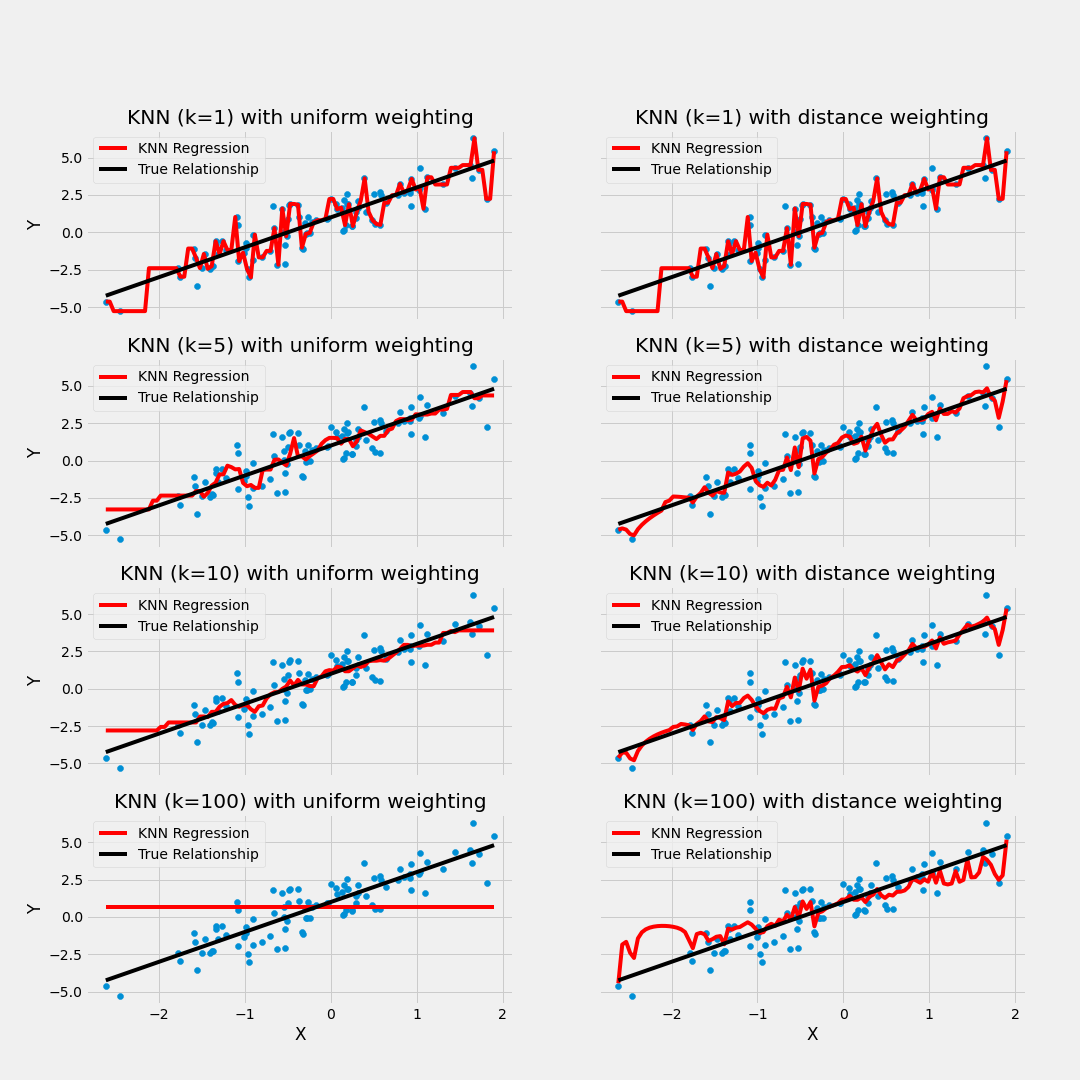
5.5.3 Ajuste del modelo
En contraste con otros algoritmos de aprendizaje supervisado, K-NN no genera un modelo del aprendizaje con datos de entrenamiento, sino que el aprendizaje sucede en el mismo momento en el que se prueban los datos de prueba. A este tipo de algoritmos se les llama lazy learning methods porque no aprende del conjunto de entrenamiento inmediatamente, sino que almacena el conjunto de datos y, en el momento de la clasificación, realiza una acción en el conjunto de datos.
El algoritmo KNN en la fase de entrenamiento simplemente almacena el conjunto de datos y cuando obtiene nuevos datos, clasifica esos datos en una categoría que es muy similar a los nuevos datos.
5.5.3.1 Selección de Hiper-parámetro K
Al configurar un modelo KNN, sólo hay algunos parámetros que deben elegirse/ajustarse para mejorar el rendimiento, uno de estos parámetros es el valor de la K.
No existe una forma particular de determinar el mejor valor para “K,” por lo que debemos probar algunos valores para encontrar “el mejor” de ellos.
Para los modelos de clasificación, especialmente si solo hay dos clases, generalmente se elige un número impar para k. Esto es para que el algoritmo nunca llegue a un “empate”
Una opción para seleccionar la K adecuada es ejecutar el algoritmo KNN varias veces con diferentes valores de K y elegimos la K que reduce la cantidad de errores mientras se mantiene la capacidad del algoritmo para hacer predicciones con precisión.
Observemos lo siguiente:

Estas gráficas se conoce como “gráfica de codo” y generalmente se usan para determinar el valor K.
A medida que disminuimos el valor de K a 1, nuestras predicciones se vuelven menos estables. Imaginemos que tomamos K = 1 y tenemos un punto de consulta rodeado por varios rojos y uno verde, pero el verde es el vecino más cercano. Razonablemente, pensaríamos que el punto de consulta es probablemente rojo, pero como K = 1, KNN predice incorrectamente que el punto de consulta es verde.
Inversamente, a medida que aumentamos el valor de K, nuestras predicciones se vuelven más estables debido a que tenemos más observaciones con quienes comparar, por lo tanto, es más probable que hagan predicciones más precisas. Eventualmente, comenzamos a presenciar un número creciente de errores, es en este punto que sabemos que hemos llevado el valor de K demasiado lejos.
5.5.3.2 Métodos de cálculo de la distancia entre observaciones
Otro parámetro que podemos ajustar para el modelo es la distancia usada, existen diferentes formas de medir qué tan “cerca” están dos puntos entre sí, y las diferencias entre estos métodos pueden volverse significativas en dimensiones superiores.
- La más utilizada es la distancia euclidiana, el tipo estándar de distancia.
\[d(X,Y) = \sqrt{\sum_{i=1}^{n} (x_i-y_i)^2}\]
- Otra métrica es la llamada distancia de Manhattan, que mide la distancia tomada en cada dirección cardinal, en lugar de a lo largo de la diagonal.
\[d(X,Y) = \sum_{i=1}^{n} |x_i - y_i|\]
- De manera más general, las anteriores son casos particulares de la distancia de Minkowski, cuya fórmula es:
\[d(X,Y) = (\sum_{i=1}^{n} |x_i-y_i|^p)^{\frac{1}{p}}\]
- La distancia de coseno es ampliamente en análisis de texto, sistemas de recomendación
\[d(X,Y)= 1 - \frac{\sum_{i=1}^{n}{X_iY_i}}{\sqrt{\sum_{i=1}^{n}{X_i^2}}\sqrt{\sum_{i=1}^{n}{Y_i^2}}}\]
5.5.4 Implementación en R
Usaremos las recetas antes implementadas para ajustar tanto el modelo de regresión como el de clasificación. Exploraremos un conjunto de hiperparámetros para elegir el mejor modelo.
5.5.4.1 Regresión
knn_model <- nearest_neighbor(
mode = "regression",
neighbors = tune("K"),
weight_func = tune()) %>%
set_engine("kknn")
knn_workflow <- workflow() %>%
add_recipe(receta_casas) %>%
add_model(knn_model)
knn_parameters_set <- parameters(knn_workflow) %>%
update(K = dials::neighbors(c(10,80)),
weight_func = weight_func(values = c("rectangular", "inv", "gaussian", "cos"))
)
set.seed(123)
knn_grid <- knn_parameters_set %>%
grid_max_entropy(size = 150)
ctrl_grid <- control_grid(save_pred = T, verbose = T)library(doParallel)
UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
casas_folds <- vfold_cv(ames_train)
knnt1 <- Sys.time()
knn_tune_result <- tune_grid(
knn_workflow,
resamples = casas_folds,
grid = knn_grid,
metrics = metric_set(rmse, mae, mape),
control = ctrl_grid
)
knnt2 <- Sys.time(); knnt2 - knnt1
stopCluster(cluster)
knn_tune_result %>% saveRDS("models/knn_model_reg.rds")Podemos obtener las métricas de cada fold con el siguiente código:
knn_tune_result <- readRDS("models/knn_model_reg.rds")
knn_tune_result %>% unnest(.metrics)## # A tibble: 3,660 × 10
## splits id K weight_func .metric .estimator .estimate
## <list> <chr> <int> <chr> <chr> <chr> <dbl>
## 1 <split [1845/206]> Fold01 11 cos rmse standard 0.246
## 2 <split [1845/206]> Fold01 12 cos rmse standard 0.245
## 3 <split [1845/206]> Fold01 22 cos rmse standard 0.247
## 4 <split [1845/206]> Fold01 27 cos rmse standard 0.248
## 5 <split [1845/206]> Fold01 28 cos rmse standard 0.248
## 6 <split [1845/206]> Fold01 30 cos rmse standard 0.248
## 7 <split [1845/206]> Fold01 33 cos rmse standard 0.249
## 8 <split [1845/206]> Fold01 35 cos rmse standard 0.249
## 9 <split [1845/206]> Fold01 37 cos rmse standard 0.249
## 10 <split [1845/206]> Fold01 39 cos rmse standard 0.249
## # … with 3,650 more rows, and 3 more variables: .config <chr>, .notes <list>,
## # .predictions <list>En la siguiente gráfica observamos el error cuadrático medio de las distintas métricas con distintos números de vecinos.
En los argumentos de la funcion, se puede seleccionar el kernel, esto es las opciones posibles para ponderar el promedio respecto a la distancia seleccinada. “Rectangular” (que es knn estándar no ponderado), “triangular,” “cos,” “inv,” “gaussiano,” “rango” y “óptimo.”
Para conocer más a cerca de las distintas métricas de distancia pueden consultar: Measures y KNN function
knn_tune_result %>%
autoplot(metric = "rmse")
En la siguiente gráfica observamos el error absoluto promedio de las distintas métricas con distintos números de vecinos.
knn_tune_result %>%
autoplot(metric = "mae")
Con el siguiente código obtenemos los mejores 10 modelos respecto al rmse.
show_best(knn_tune_result, n = 10, metric = "rmse")## # A tibble: 10 × 8
## K weight_func .metric .estimator mean n std_err .config
## <int> <chr> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 12 cos rmse standard 0.203 10 0.00892 Preprocessor1_Model…
## 2 22 cos rmse standard 0.203 10 0.00887 Preprocessor1_Model…
## 3 11 cos rmse standard 0.203 10 0.00885 Preprocessor1_Model…
## 4 27 cos rmse standard 0.204 10 0.00887 Preprocessor1_Model…
## 5 28 cos rmse standard 0.204 10 0.00890 Preprocessor1_Model…
## 6 30 cos rmse standard 0.204 10 0.00888 Preprocessor1_Model…
## 7 13 gaussian rmse standard 0.204 10 0.00873 Preprocessor1_Model…
## 8 15 gaussian rmse standard 0.205 10 0.00868 Preprocessor1_Model…
## 9 11 gaussian rmse standard 0.205 10 0.00855 Preprocessor1_Model…
## 10 33 cos rmse standard 0.205 10 0.00890 Preprocessor1_Model…Ahora obtendremos el modelo que mejor desempeño tiene tomando en cuenta el rmse y haremos las predicciones del conjunto de prueba con este modelo.
best_knn_model_reg <- select_best(knn_tune_result, metric = "rmse")
final_knn_model_reg <- knn_workflow %>%
finalize_workflow(best_knn_model_reg) %>%
parsnip::fit(data = ames_train)
results_reg <- predict(final_knn_model_reg, ames_test) %>%
dplyr::bind_cols(truth = ames_test$Sale_Price) %>%
mutate(.pred = exp(.pred) )Métricas de desempeño
Ahora para calcular las métricas de desempeño usaremos la paqueteria MLmetrics
library(MLmetrics)
results_reg %>%
summarise(
mae = MLmetrics::MAE(.pred, truth),
mape = MLmetrics::MAPE(.pred, truth),
rmse = MLmetrics::RMSE(.pred, truth),
r2 = MLmetrics::R2_Score(.pred, truth),
rmsle = MLmetrics::RMSLE(.pred, truth)
)## # A tibble: 1 × 5
## mae mape rmse r2 rmsle
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 25772. 0.146 40840. 0.743 0.2095.5.4.2 Clasificación
Repetiremos el proceso para el problema de clasificación.
knn_model <- nearest_neighbor(
mode = "classification",
neighbors = tune("K"),
weight_func = tune()) %>%
set_engine("kknn")
knn_workflow <- workflow() %>%
add_recipe(telco_rec) %>%
add_model(knn_model)
knn_parameters_set <- parameters(knn_workflow) %>%
update(K = dials::neighbors(c(10,80)),
weight_func = weight_func(values = c("rectangular", "inv", "gaussian", "cos"))
)
set.seed(123)
knn_grid <- knn_parameters_set %>%
grid_max_entropy(size = 150)
ctrl_grid <- control_grid(save_pred = T, verbose = T)library(doParallel)
UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
telco_folds <- vfold_cv(telco_train)
knnt1 <- Sys.time()
knn_tune_result <- tune_grid(
knn_workflow,
resamples = telco_folds,
grid = knn_grid,
metrics = metric_set(roc_auc, pr_auc, sens),
control = ctrl_grid
)
knnt2 <- Sys.time(); knnt2 - knnt1
stopCluster(cluster)
knn_tune_result %>% saveRDS("models/knn_model_cla.rds")knn_tune_result <- readRDS("models/knn_model_cla.rds")autoplot(knn_tune_result, metric = "pr_auc")
autoplot(knn_tune_result, metric = "roc_auc")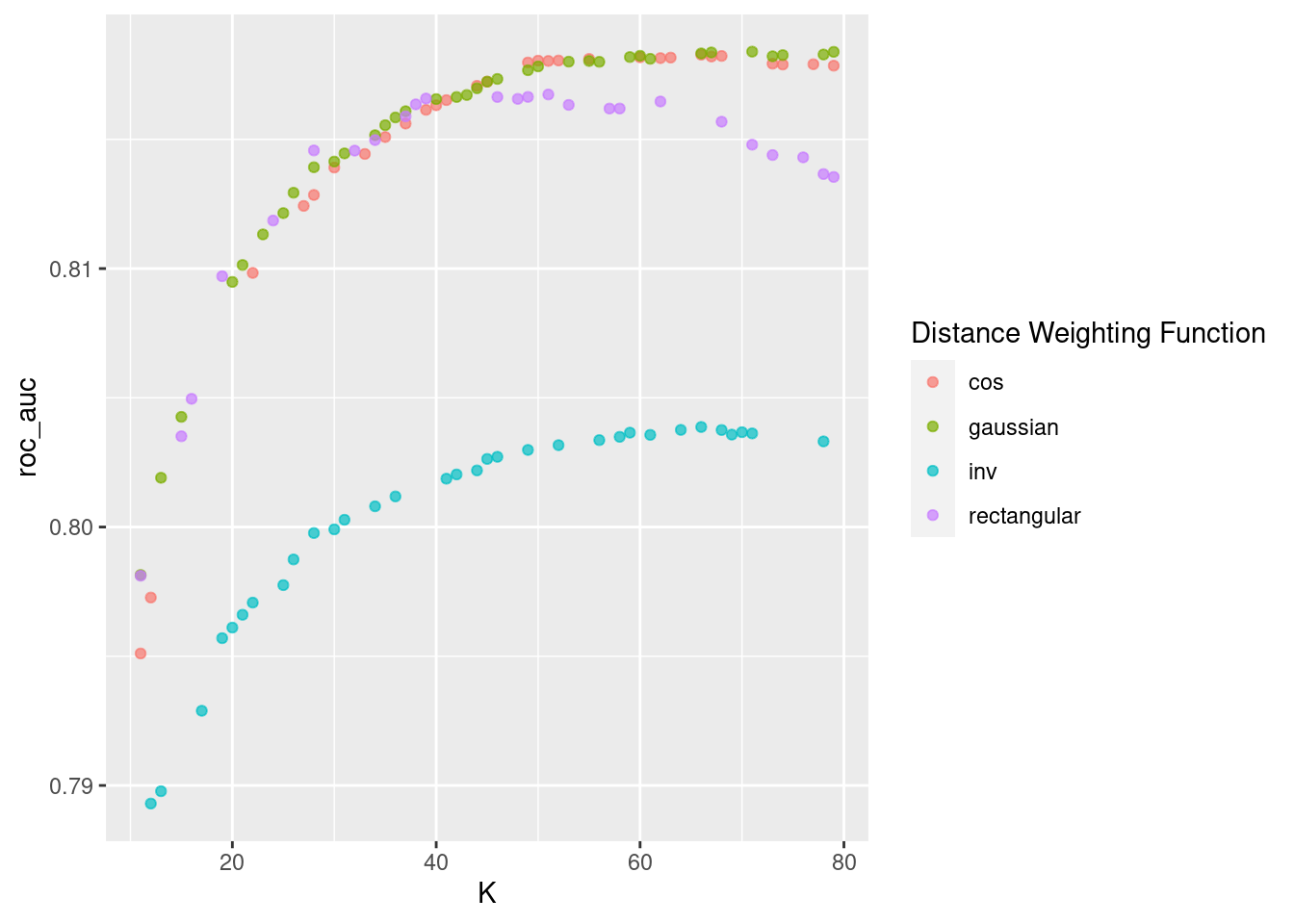
show_best(knn_tune_result, n = 10, metric = "pr_auc")## # A tibble: 10 × 8
## K weight_func .metric .estimator mean n std_err .config
## <int> <chr> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 79 gaussian pr_auc binary 0.925 10 0.00268 Preprocessor1_Model…
## 2 78 gaussian pr_auc binary 0.925 10 0.00270 Preprocessor1_Model…
## 3 71 gaussian pr_auc binary 0.924 10 0.00276 Preprocessor1_Model…
## 4 74 gaussian pr_auc binary 0.924 10 0.00275 Preprocessor1_Model…
## 5 79 cos pr_auc binary 0.924 10 0.00272 Preprocessor1_Model…
## 6 77 cos pr_auc binary 0.924 10 0.00274 Preprocessor1_Model…
## 7 73 gaussian pr_auc binary 0.924 10 0.00276 Preprocessor1_Model…
## 8 67 gaussian pr_auc binary 0.924 10 0.00280 Preprocessor1_Model…
## 9 66 gaussian pr_auc binary 0.924 10 0.00281 Preprocessor1_Model…
## 10 68 cos pr_auc binary 0.924 10 0.00278 Preprocessor1_Model…best_knn_model_cla <- select_best(knn_tune_result, metric = "pr_auc")
final_knn_model_cla <- knn_workflow %>%
finalize_workflow(best_knn_model_cla) %>%
parsnip::fit(data = telco_train)
results_cla <- predict(final_knn_model_cla, telco_test, type = 'prob') %>%
dplyr::bind_cols(truth =telco_test$Churn) %>%
mutate(truth = factor(truth, levels = c('No', 'Yes'), labels = c('No', 'Yes')))
head(results_cla, 10)## # A tibble: 10 × 3
## .pred_No .pred_Yes truth
## <dbl> <dbl> <fct>
## 1 0.887 0.113 No
## 2 0.290 0.710 Yes
## 3 0.750 0.250 No
## 4 0.933 0.0669 No
## 5 0.857 0.143 No
## 6 0.554 0.446 No
## 7 0.950 0.0498 No
## 8 0.846 0.154 No
## 9 0.665 0.335 Yes
## 10 0.982 0.0182 Nopr_curve_data <- pr_curve(
results_cla,
truth = truth,
estimate = .pred_Yes,
event_level = 'second'
)
roc_curve_data <- roc_curve(
results_cla,
truth = truth,
estimate = .pred_Yes,
event_level = 'second'
)pr_curve_plot <- pr_curve_data %>%
ggplot(aes(x = recall, y = precision)) +
geom_path(size = 1, colour = 'lightblue') +
coord_equal() +
ggtitle("Precision vs Recall")+
theme_minimal()
pr_curve_plot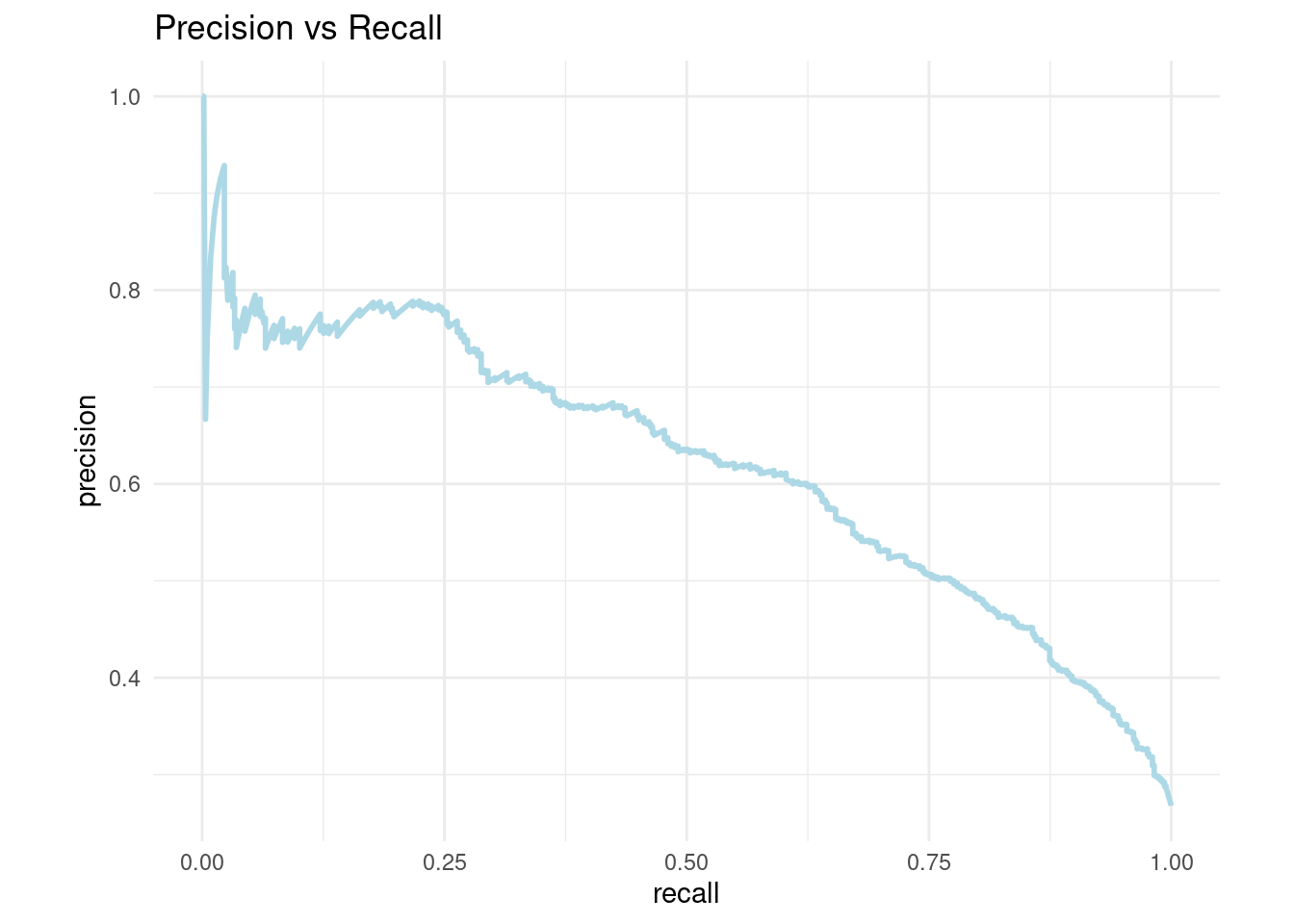
roc_curve_plot <- roc_curve_data %>%
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_path(size = 1, colour = 'lightblue') +
geom_abline() +
coord_equal() +
ggtitle("ROC Curve")+
theme_minimal()
roc_curve_plot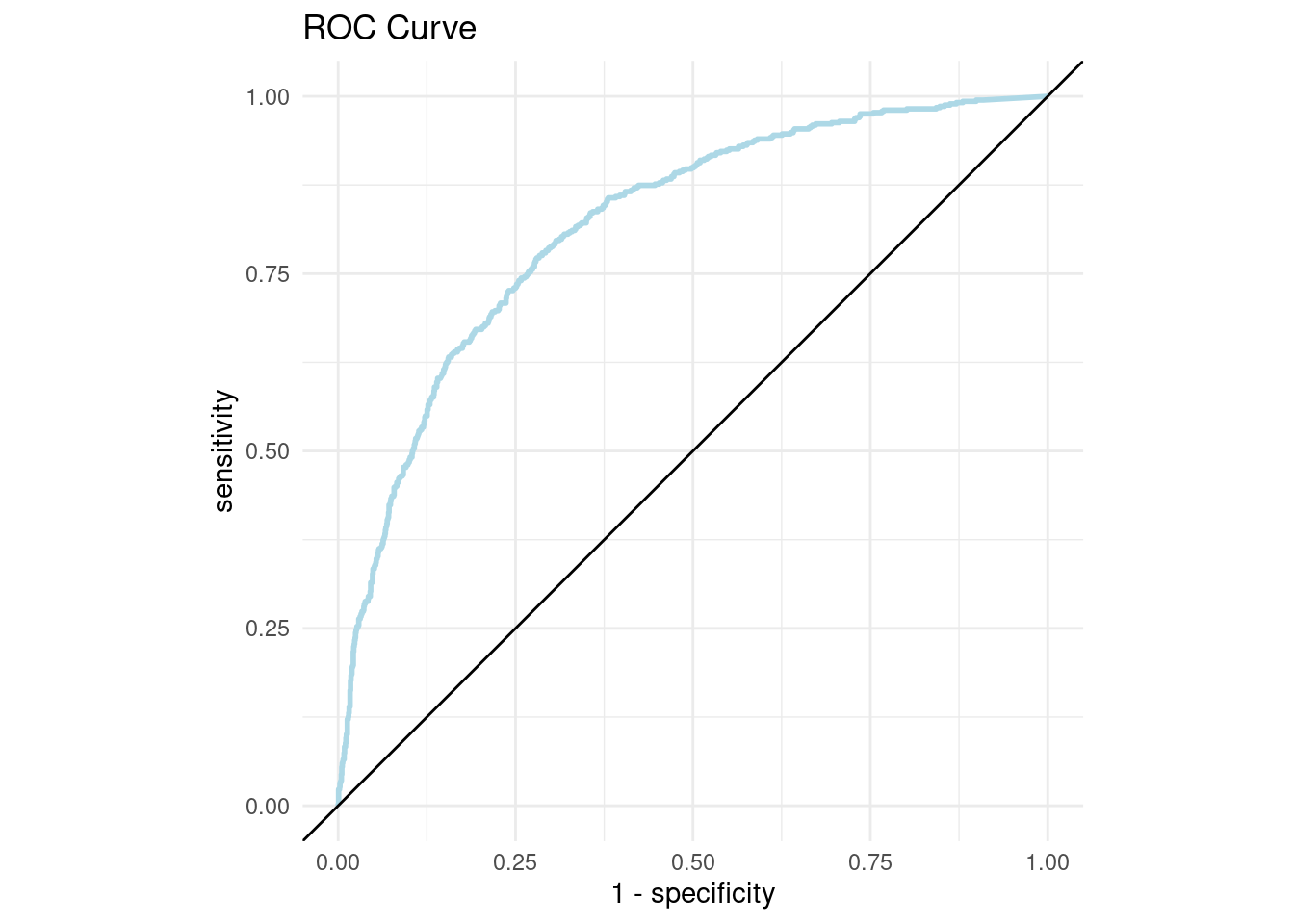
5.6 Árboles de decisión
Un árbol de decisiones es un algoritmo del aprendizaje supervisado que se puede utilizar tanto para problemas de clasificación como de regresión. Es un clasificador estructurado en árbol, donde los nodos internos representan las características de un conjunto de datos, las ramas representan las reglas de decisión y cada nodo hoja representa el resultado. La idea básica de los árboles es buscar puntos de cortes en las variables de entrada para hacer predicciones, ir dividiendo la muestra, y encontrar cortes sucesivos para refinar las predicciones.
En un árbol de decisión, hay dos tipos nodos, el nodo de decisión o nodos internos (Decision Node) y el nodo hoja o nodo terminal (Leaf node). Los nodos de decisión se utilizan para tomar cualquier decisión y tienen múltiples ramas, mientras que los nodos hoja son el resultado de esas decisiones y no contienen más ramas.
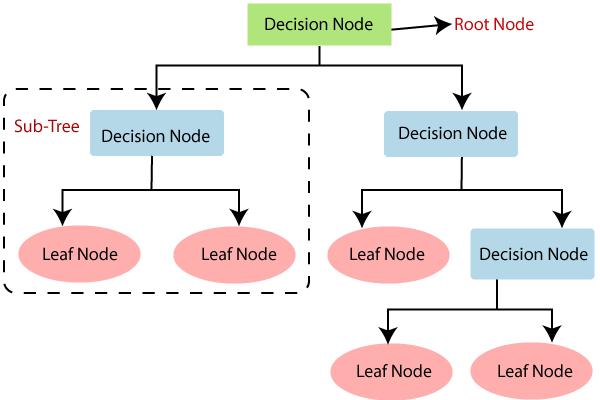
- Regresión:
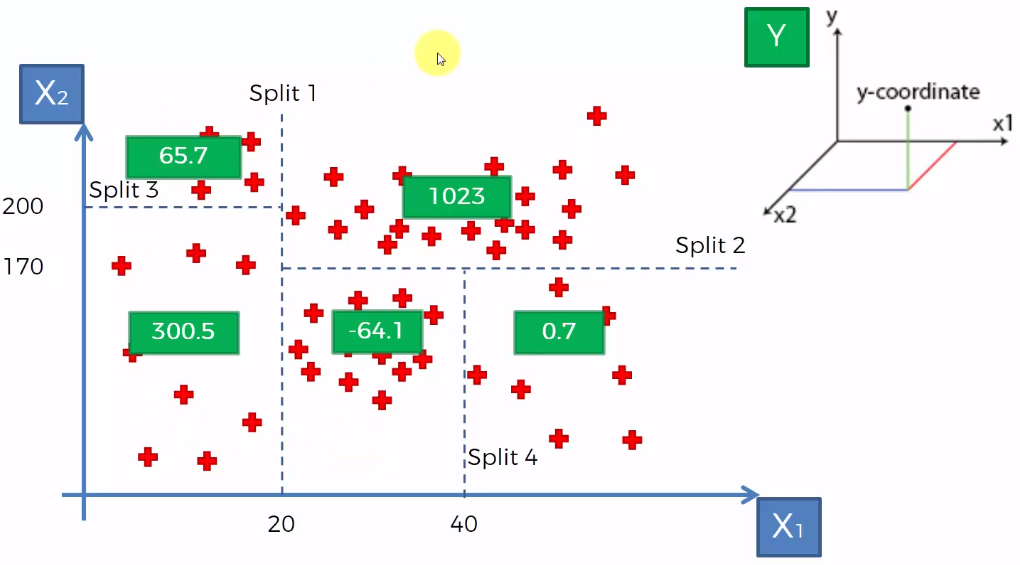
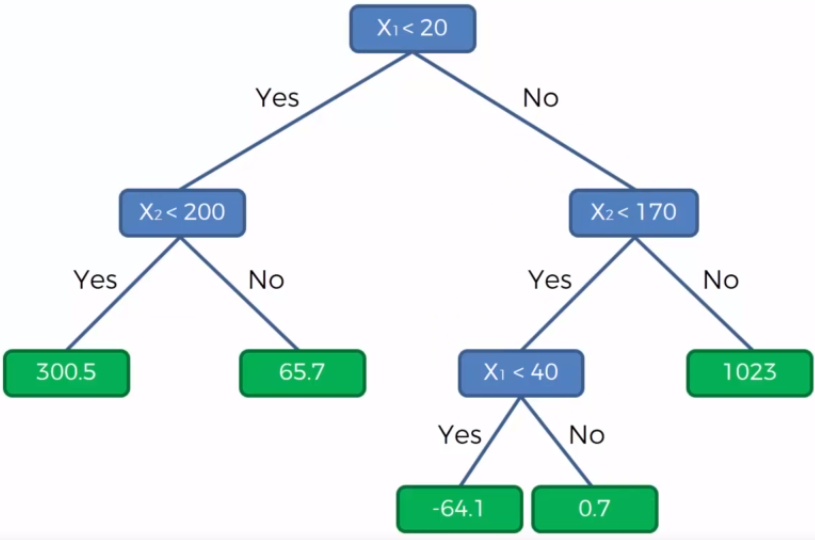
- Clasificación:

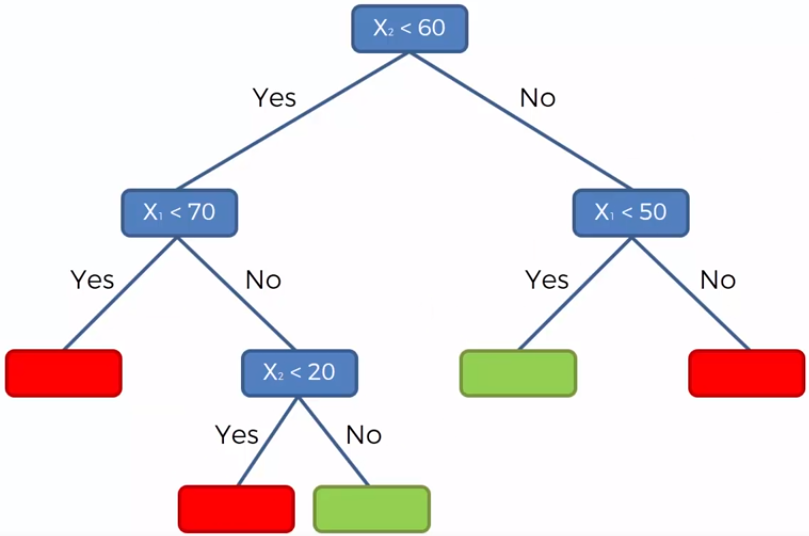
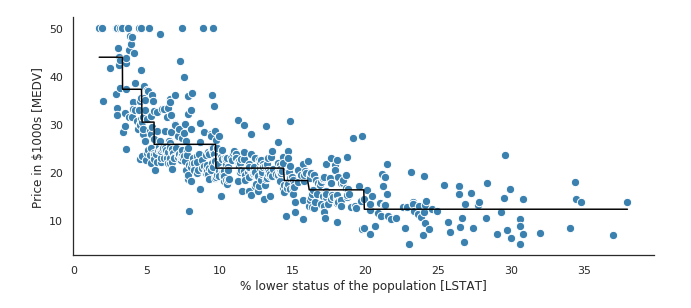
5.6.1 Ajuste del modelo
En un árbol de decisión, para predecir la clase del conjunto de datos, el algoritmo comienza desde el nodo raíz del árbol. Este algoritmo compara los valores de la variable raíz con la variable de registro y, según la comparación, sigue una rama y salta al siguiente nodo.
Para el siguiente nodo, el algoritmo vuelve a comparar el valor de la siguiente variable con los otros subnodos y avanza. Continúa el proceso hasta que se llega a un nodo hoja. El proceso completo se puede comprender mejor con los siguientes pasos:
Comenzamos el árbol con el nodo raíz, llamémoslo S, que contiene el conjunto de entrenamiento completo.
Encuentre la mejor variable en el conjunto de datos usando Attribute Selective Measure (ASM).
Divida la S en subconjuntos que contengan valores posibles para la mejor variable.
Genere el nodo del árbol de decisión, que contiene la mejor variable.
Cree de forma recursiva nuevos árboles de decisión utilizando los subconjuntos del conjunto de datos creado en el paso 3. Continúe este proceso hasta que se alcance una etapa en la que no pueda particionar más los nodos y este nodo final sera un nodo hoja.
Para clasificación nos quedaremos la moda de la variable respuesta del nodo hoja y para regresión usaremos la media de la variable respuesta.
5.6.1.1 Attribute Selective Measure (ASM)
Al implementar un árbol de decisión, surge el problema principal de cómo seleccionar la mejor variable para el nodo raíz y para los subnodos. Para resolver este problemas existe una técnica que se llama medida de selección de atributos o ASM. Mediante esta medición, podemos seleccionar fácilmente la mejor variable para los nodos del árbol. Hay dos técnicas populares para ASM, que son:
- Índice de Gini
La medida del grado de probabilidad de que una variable en particular se clasifique incorrectamente cuando se elige al azar se llama índice de Gini o impureza de Gini. Los datos se distribuyen por igual según el índice de Gini.
\[Gini = \sum_{i=1}^{n}\hat{p_i}(1-\hat{p}_i)\]
Con \(p_i\) como la probabilidad de que un objeto se clasifique en una clase particular.
Esta métrica puede analizarse como una métrica de impureza. Cuando todos o la mayoría de elementos dentro de un nodo pertenecen a una misma clase, el índice de Gini toma valores cercanos a cero.
Cuando se utiliza el índice de Gini como criterio seleccionar la variable para el nodo raíz, seleccionaremos la variable con el índice de Gini menor.
5.6.1.2 ¿Cuándo dejar de dividir un nodo?
Podríamos preguntarnos cuándo dejar de crecer un árbol. Pueden existir problemas que tengan un gran conjunto de variables y esto da como resultado una gran cantidad de divisiones, lo que a su vez genera un árbol de decisión muy grande. Estos árboles son complejos y pueden provocar un sobreajuste. Entonces, necesitamos saber cuándo parar.
Una forma de hacer esto es establecer un número mínimo de entradas de entrenamiento para dividir un nodo.
Otra forma es establecer la profundidad máxima de su modelo. La profundidad máxima se refiere a la longitud del camino más largo desde el nodo raíz hasta un nodo hoja.
5.6.1.3 ¿Cuándo podar un árbol?
El rendimiento de un árbol se puede aumentar aún más mediante la poda del árbol. Esto se refiere a eliminar las ramas que hacen uso de variables de poca importancia. De esta manera, reducimos la complejidad del árbol y, por lo tanto, aumentamos su poder predictivo al reducir el sobreajuste.

La poda puede comenzar en la raíz o en las hojas. El método más simple de poda comienza en las hojas y elimina cada nodo con la clase más popular en esa hoja, este cambio se mantiene si no deteriora la precisión. Se pueden usar métodos de poda más sofisticados, como la poda de complejidad de costos, donde se usa un parámetro de aprendizaje (alfa) para observar si los nodos se pueden eliminar en función del tamaño del subárbol.
5.6.2 Implementación en R
Usaremos las recetas antes implementadas para ajustar tanto el modelo de regresión como el de clasificación. Exploraremos un conjunto de hiperparámetros para elegir el mejor modelo. En esta ocasión usamos la función grid_regular() donde con el parámetro levels le indicamos cuantos distintos números queremos para cada parámetro a ajustar.
5.6.2.1 Regresión:
tree_model <- decision_tree(
mode = "regression",
tree_depth = tune(),
cost_complexity = tune(),
min_n = tune()) %>%
set_engine("rpart")
tree_workflow <- workflow() %>%
add_recipe(receta_casas) %>%
add_model(tree_model)
tree_grid <- grid_regular(
min_n(),
tree_depth(),
cost_complexity(),
levels = 5
)
ctrl_grid <- control_grid(save_pred = T, verbose = T)UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
casas_folds <- vfold_cv(ames_train)
knnt1 <- Sys.time()
tree_tune_result <- tune_grid(
tree_workflow,
resamples = casas_folds,
grid = tree_grid,
metrics = metric_set(rmse, mae, mape),
control = ctrl_grid
)
knnt2 <- Sys.time(); knnt2 - knnt1
stopCluster(cluster)
tree_tune_result %>% saveRDS("models/tree_model_reg.rds")Podemos obtener las métricas de cada fold con el siguiente código:
tree_tune_result <- readRDS("models/tree_model_reg.rds")
tree_tune_result %>% unnest(.metrics)## # A tibble: 3,750 × 11
## splits id cost_complexity tree_depth min_n .metric .estimator
## <list> <chr> <dbl> <int> <int> <chr> <chr>
## 1 <split [1977/220]> Fold01 0.0000000001 1 2 rmse standard
## 2 <split [1977/220]> Fold01 0.0000000001 1 2 mae standard
## 3 <split [1977/220]> Fold01 0.0000000001 1 2 mape standard
## 4 <split [1977/220]> Fold01 0.0000000001 1 11 rmse standard
## 5 <split [1977/220]> Fold01 0.0000000001 1 11 mae standard
## 6 <split [1977/220]> Fold01 0.0000000001 1 11 mape standard
## 7 <split [1977/220]> Fold01 0.0000000001 1 21 rmse standard
## 8 <split [1977/220]> Fold01 0.0000000001 1 21 mae standard
## 9 <split [1977/220]> Fold01 0.0000000001 1 21 mape standard
## 10 <split [1977/220]> Fold01 0.0000000001 1 30 rmse standard
## # … with 3,740 more rows, and 4 more variables: .estimate <dbl>, .config <chr>,
## # .notes <list>, .predictions <list>En la siguiente gráfica observamos el error cuadrático medio de las distintas métricas con distintos números de vecinos.
tree_tune_result %>% autoplot(metric = "rmse")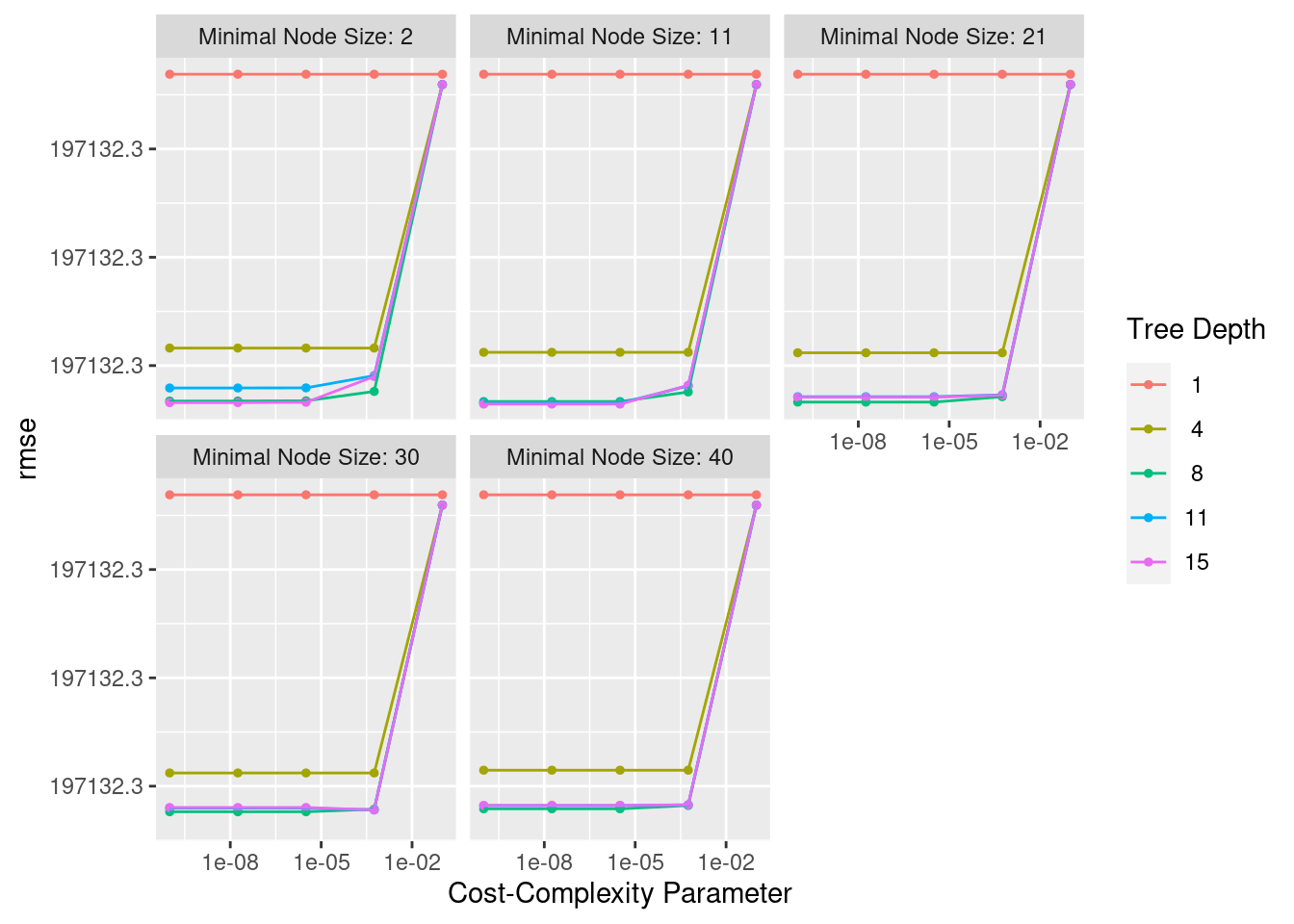
En la siguiente gráfica observamos el error absoluto promedio de las distintas métricas con distintos números de vecinos.
tree_tune_result %>% autoplot(metric = "mae")
Con el siguiente código obtenemos los mejores 10 modelos respecto al rmse.
show_best(tree_tune_result, n = 10, metric = "rmse")## # A tibble: 10 × 9
## cost_complexity tree_depth min_n .metric .estimator mean n std_err
## <dbl> <int> <int> <chr> <chr> <dbl> <int> <dbl>
## 1 0.0000000001 15 11 rmse standard 197132. 10 3010.
## 2 0.0000000178 15 11 rmse standard 197132. 10 3010.
## 3 0.00000316 15 11 rmse standard 197132. 10 3010.
## 4 0.0000000001 11 11 rmse standard 197132. 10 3010.
## 5 0.0000000178 11 11 rmse standard 197132. 10 3010.
## 6 0.00000316 11 11 rmse standard 197132. 10 3010.
## 7 0.0000000001 15 2 rmse standard 197132. 10 3010.
## 8 0.0000000178 15 2 rmse standard 197132. 10 3010.
## 9 0.00000316 15 2 rmse standard 197132. 10 3010.
## 10 0.0000000001 8 21 rmse standard 197132. 10 3010.
## # … with 1 more variable: .config <chr>Ahora obtendremos el modelo que mejor desempeño tiene tomando en cuenta el rmse y haremos las predicciones del conjunto de prueba con este modelo.
best_tree_model_reg <- select_best(tree_tune_result, metric = "rmse")
final_tree_model_reg <- tree_workflow %>%
finalize_workflow(best_tree_model_reg) %>%
parsnip::fit(data = ames_train)
results_reg <- predict(final_tree_model_reg, ames_test) %>%
dplyr::bind_cols(truth = ames_test$Sale_Price) %>%
mutate(.pred = exp(.pred))Nuestro árbol final se ve de la siguiente manera:
library(rpart.plot)
final_tree_model_reg %>%
extract_fit_engine() %>%
rpart.plot(roundint = FALSE)
Podemos obtener la impotancia de las variables:
library(vip)
final_tree_model_reg %>%
extract_fit_parsnip() %>%
vip() + ggtitle("Importancia de las variables")
5.6.2.1.1 Métricas de desempeño
Ahora para calcular las métricas de desempeño usaremos la paqueteria MLmetrics
library(MLmetrics)
results_reg %>%
summarise(
mae = MLmetrics::MAE(.pred, truth),
mape = MLmetrics::MAPE(.pred, truth),
rmse = MLmetrics::RMSE(.pred, truth),
r2 = MLmetrics::R2_Score(.pred, truth),
rmsle = MLmetrics::RMSLE(.pred, truth)
)## # A tibble: 1 × 5
## mae mape rmse r2 rmsle
## <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 29305. 0.172 44333. 0.697 0.2345.6.2.2 Clasificación
Repetiremos el proceso para el problema de clasificación.
tree_model <- decision_tree(
mode = "classification",
tree_depth = tune(),
cost_complexity = tune(),
min_n = tune()) %>%
set_engine("rpart")
tree_workflow <- workflow() %>%
add_recipe(telco_rec) %>%
add_model(tree_model)
tree_grid <- grid_regular(
min_n(),
tree_depth(),
cost_complexity(),
levels = 5
)
ctrl_grid <- control_grid(save_pred = T, verbose = T)library(doParallel)
UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
telco_folds <- vfold_cv(telco_train)
treet1 <- Sys.time()
tree_tune_result <- tune_grid(
tree_workflow,
resamples = telco_folds,
grid = tree_grid,
metrics = metric_set(roc_auc, pr_auc, sens),
control = ctrl_grid
)
treet2 <- Sys.time(); knnt2 - knnt1
stopCluster(cluster)
tree_tune_result %>% saveRDS("models/tree_model_cla.rds")tree_tune_result <- readRDS("models/tree_model_cla.rds")
tree_tune_result %>% unnest(.metrics)## # A tibble: 3,750 × 11
## splits id cost_complexity tree_depth min_n .metric .estimator
## <list> <chr> <dbl> <int> <int> <chr> <chr>
## 1 <split [4437/493]> Fold01 0.0000000001 1 2 sens binary
## 2 <split [4437/493]> Fold01 0.0000000001 1 2 roc_auc binary
## 3 <split [4437/493]> Fold01 0.0000000001 1 2 pr_auc binary
## 4 <split [4437/493]> Fold01 0.0000000001 1 11 sens binary
## 5 <split [4437/493]> Fold01 0.0000000001 1 11 roc_auc binary
## 6 <split [4437/493]> Fold01 0.0000000001 1 11 pr_auc binary
## 7 <split [4437/493]> Fold01 0.0000000001 1 21 sens binary
## 8 <split [4437/493]> Fold01 0.0000000001 1 21 roc_auc binary
## 9 <split [4437/493]> Fold01 0.0000000001 1 21 pr_auc binary
## 10 <split [4437/493]> Fold01 0.0000000001 1 30 sens binary
## # … with 3,740 more rows, and 4 more variables: .estimate <dbl>, .config <chr>,
## # .notes <list>, .predictions <list>tree_tune_result %>% autoplot(metric = "pr_auc")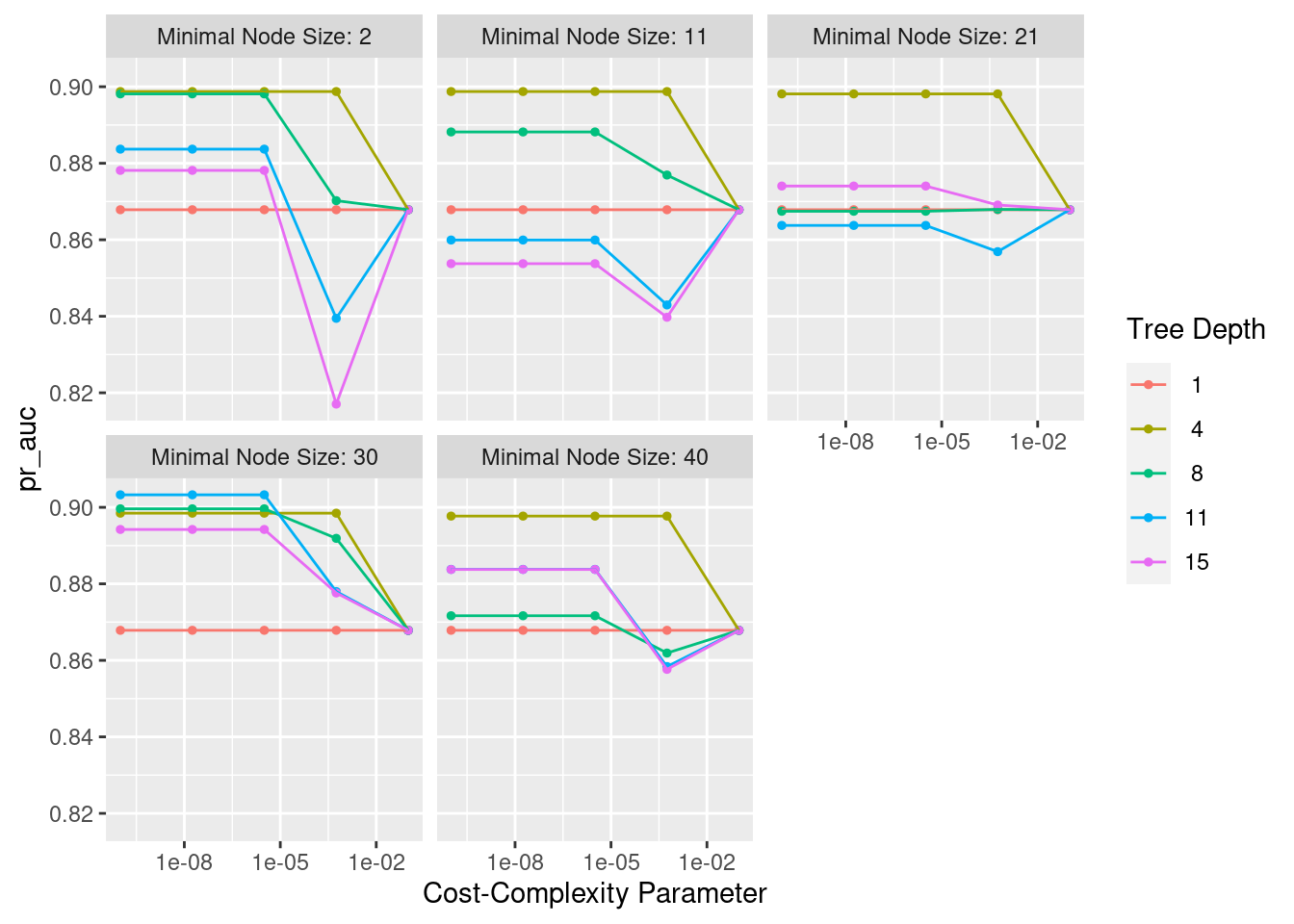
tree_tune_result %>% autoplot(metric = "roc_auc")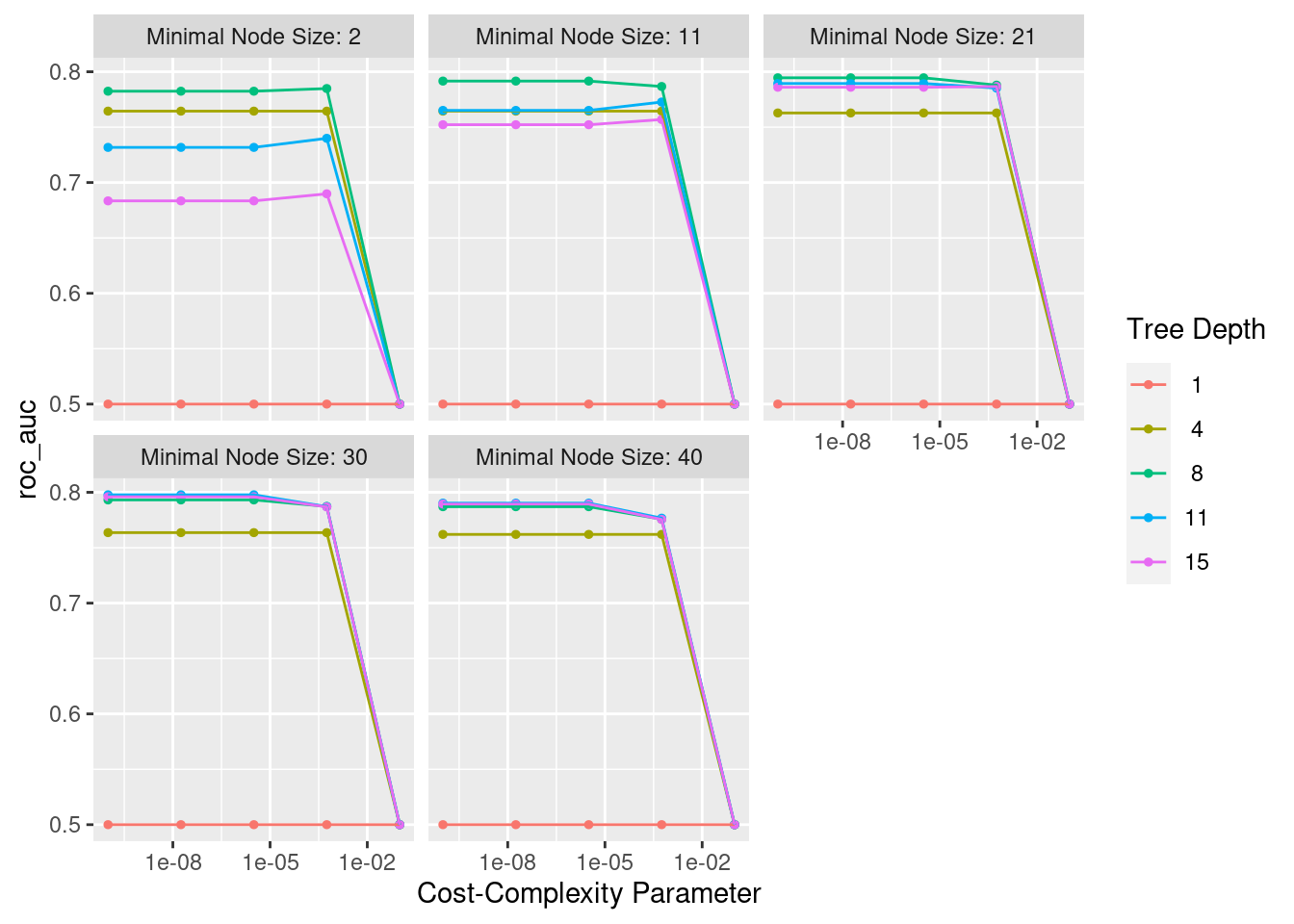
show_best(tree_tune_result, n = 10, metric = "pr_auc")## # A tibble: 10 × 9
## cost_complexity tree_depth min_n .metric .estimator mean n std_err
## <dbl> <int> <int> <chr> <chr> <dbl> <int> <dbl>
## 1 0.0000000001 11 30 pr_auc binary 0.903 10 0.00584
## 2 0.0000000178 11 30 pr_auc binary 0.903 10 0.00584
## 3 0.00000316 11 30 pr_auc binary 0.903 10 0.00584
## 4 0.0000000001 8 30 pr_auc binary 0.900 10 0.00812
## 5 0.0000000178 8 30 pr_auc binary 0.900 10 0.00812
## 6 0.00000316 8 30 pr_auc binary 0.900 10 0.00812
## 7 0.0000000001 4 2 pr_auc binary 0.899 10 0.00745
## 8 0.0000000001 4 11 pr_auc binary 0.899 10 0.00745
## 9 0.0000000178 4 2 pr_auc binary 0.899 10 0.00745
## 10 0.0000000178 4 11 pr_auc binary 0.899 10 0.00745
## # … with 1 more variable: .config <chr>best_tree_model_cla <- select_best(tree_tune_result, metric = "pr_auc")
final_tree_model_cla <- tree_workflow %>%
finalize_workflow(best_tree_model_cla) %>%
parsnip::fit(data = telco_train)
results_cla <- predict(final_tree_model_cla, telco_test, type = 'prob') %>%
dplyr::bind_cols(truth =telco_test$Churn) %>%
mutate(truth = factor(truth, levels = c('No', 'Yes'), labels = c('No', 'Yes')))
head(results_cla)## # A tibble: 6 × 3
## .pred_No .pred_Yes truth
## <dbl> <dbl> <fct>
## 1 0.918 0.0822 No
## 2 0.227 0.773 Yes
## 3 0.3 0.7 No
## 4 0.981 0.0186 No
## 5 0.881 0.119 No
## 6 0.652 0.348 Noresults_cla_tree <- results_clapr_curve_data <- pr_curve(
results_cla,
truth = truth,
estimate = .pred_Yes,
event_level = 'second'
)
roc_curve_data <- roc_curve(
results_cla,
truth = truth,
estimate = .pred_Yes,
event_level = 'second'
)pr_curve_plot <- pr_curve_data %>%
ggplot(aes(x = recall, y = precision)) +
geom_path(size = 1, colour = 'lightblue') +
ylim(c(0,1)) +
coord_equal() +
ggtitle("Precision vs Recall")+
theme_minimal()
pr_curve_plot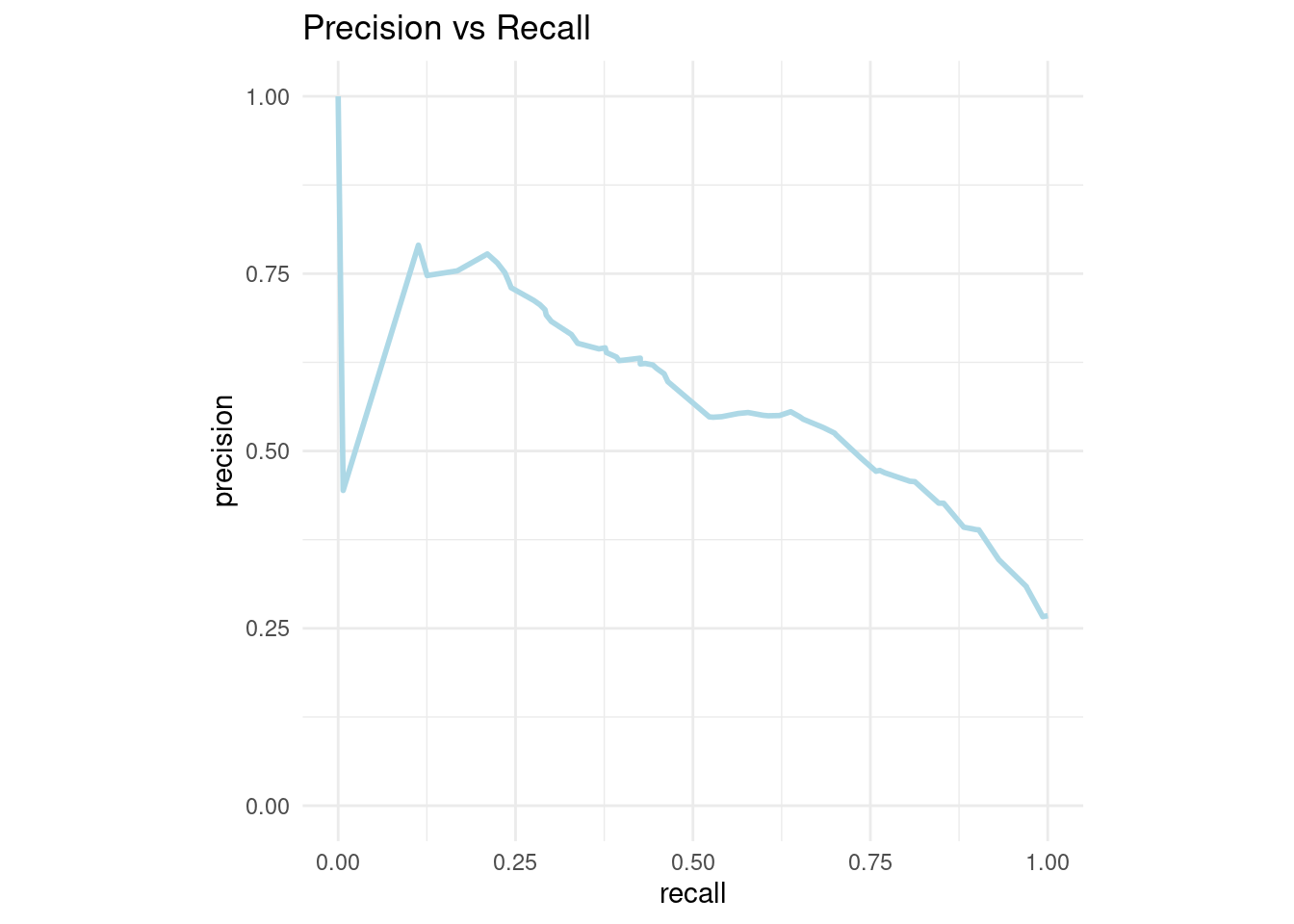
roc_curve_plot <- roc_curve_data %>%
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_path(size = 1, colour = 'lightblue') +
geom_abline() +
coord_equal() +
ggtitle("ROC Curve")+
theme_minimal()
roc_curve_plot
Nuestro árbol final se ve de la siguiente manera:
library(rpart.plot)
final_tree_model_cla %>%
extract_fit_engine() %>%
rpart.plot(roundint = FALSE)## Warning: labs do not fit even at cex 0.15, there may be some overplotting
Podemos obtener la impotancia de las variables:
library(vip)
final_tree_model_cla %>%
extract_fit_parsnip() %>%
vip() + ggtitle("Importancia de las variables")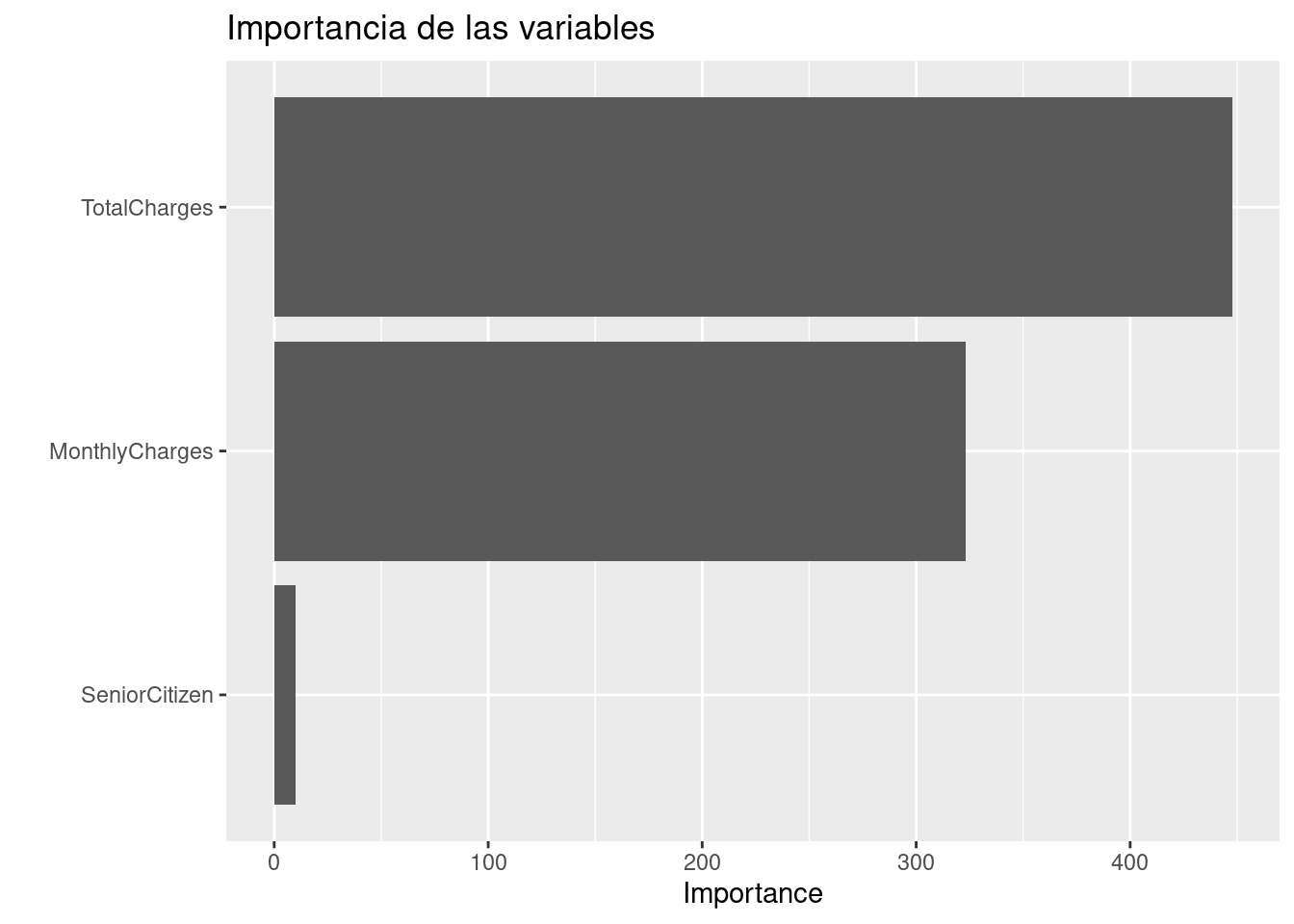
library(magrittr)
results_cla %<>% mutate(truth = as_factor(truth))5.7 Bagging
Primero tenemos que definir qué es la Agregación de Bootstrap o Bagging. Este es un aalgoritmo de aprendizaje automático diseñado para mejorar la estabilidad y precisión de algoritmos de ML usados en clasificación estadística y regresión. Además reduce la varianza y ayuda a evitar el sobreajuste. Aunque es usualmente aplicado a métodos de árboles de decisión, puede ser usado con cualquier tipo de método. Bagging es un caso especial del promediado de modelos.
Los métodos de bagging son métodos donde los algoritmos simples son usados en paralelo. El principal objetivo de los métodos en paralelo es el de aprovecharse de la independencia que hay entre los algoritmos simples, ya que el error se puede reducir bastante al promediar las salidas de los modelos simples. Es como si, queriendo resolver un problema entre varias personas independientes unas de otras, damos por bueno lo que eligiese la mayoría de las personas.
Para obtener la agregación de las salidas de cada modelo simple e independiente, bagging puede usar la votación para los métodos de clasificiación y el promedio para los métodos de regresión.
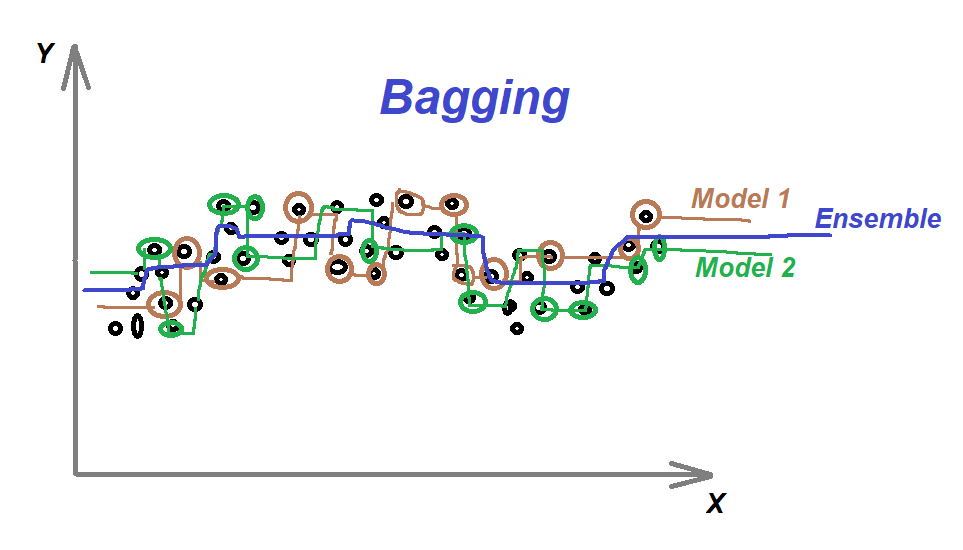
5.8 Random Forest
Un bosque aleatorio es un algoritmo de aprendizaje automático supervisado que se construye a partir de algoritmos de árbol de decisión. Este algoritmo se aplica en diversas industrias, como la banca y el comercio electrónico, para predecir el comportamiento y los resultados.
En esta clase se dará una descripción general del algoritmo de bosque aleatorio, cómo funciona y las características del algoritmo.
También se señalan las ventajas y desventajas de este algoritmo.
5.8.1 ¿Qué es?
Un bosque aleatorio es una técnica de aprendizaje automático que se utiliza para resolver problemas de regresión y clasificación. Utiliza el aprendizaje por conjuntos, que es una técnica que combina muchos clasificadores para proporcionar soluciones a problemas complejos.
Este algoritmo consta de muchos árboles de decisión. El “bosque” generado se entrena mediante agregación de bootstrap (bagging), el cual es es un meta-algoritmo de conjunto que mejora la precisión de los algoritmos de aprendizaje automático.
El algoritmo establece el resultado en función de las predicciones de los árboles de decisión. Predice tomando el promedio o la media de la salida de varios árboles. El aumento del número de árboles aumenta la precisión del resultado.
Un bosque aleatorio erradica las limitaciones de un algoritmo de árbol de decisión. Reduce el sobreajuste de conjuntos de datos y aumenta la precisión. Genera predicciones sin requerir muchas configuraciones.
5.8.2 Características de los bosques aleatorios
Es más preciso que el algoritmo árbol de decisiones.
Proporciona una forma eficaz de gestionar los datos faltantes.
Puede producir una predicción razonable sin ajuste de hiperparámetros.
Resuelve el problema del sobreajuste en los árboles de decisión.
En cada árbol forestal aleatorio, se selecciona aleatoriamente un subconjunto de características en el punto de división del nodo.
5.8.3 Aplicar árboles de decisión en un bosque aleatorio
La principal diferencia entre el algoritmo de árbol de decisión y el algoritmo de bosque aleatorio es que el establecimiento de nodos raíz y la desagregación de nodos se realiza de forma aleatoria en este último. El bosque aleatorio emplea el método de bagging para generar la predicción requerida.
El método bagging implica el uso de diferentes muestras de datos (datos de entrenamiento) en lugar de una sola muestra. Los árboles de decisión producen diferentes resultados, dependiendo de los datos de entrenamiento alimentados al algoritmo de bosque aleatorio.
Nuestro primer ejemplo todavía se puede utilizar para explicar cómo funcionan los bosques aleatorios. Supongamos que solo tenemos cuatro árboles de decisión. En este caso, los datos de entrenamiento que comprenden las observaciones y características de estudio se dividirán en cuatro nodos raíz. Supongamos que queremos modelar si un cliente compra o no compra un teléfono.
Los nodos raíz podrían representar cuatro características que podrían influir en la elección de un cliente (precio, almacenamiento interno, cámara y RAM). El bosque aleatorio dividirá los nodos seleccionando características al azar. La predicción final se seleccionará en función del resultado de los cuatro árboles.
El resultado elegido por la mayoría de los árboles de decisión será la elección final.
Si tres árboles predicen la compra y un árbol predice que no comprará, entonces la predicción final será la compra. En este caso, se prevé que el cliente comprará.
El siguiente diagrama muestra un clasificador de bosque aleatorio simple.

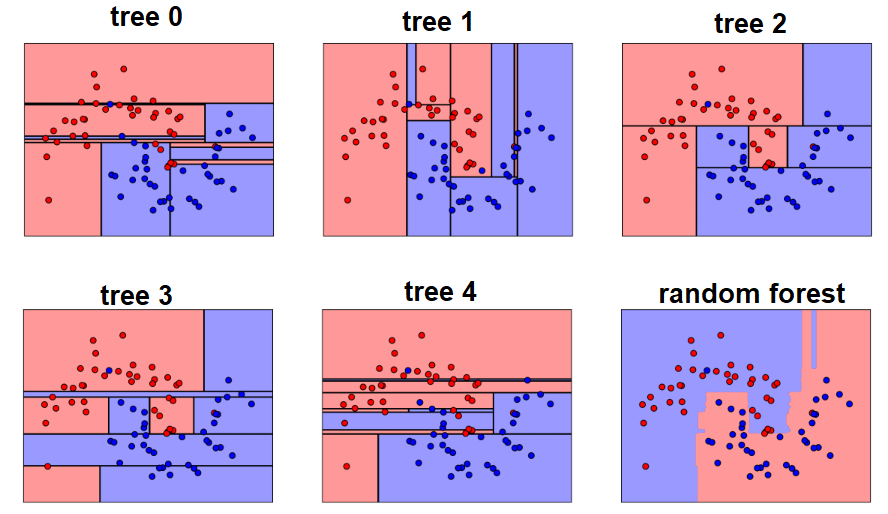
5.8.4 Ventajas y desventjas de bosques aleatorios
Ventajas
Puede realizar tareas de regresión y clasificación.
Un bosque aleatorio produce buenas predicciones que se pueden entender fácilmente.
Puede manejar grandes conjuntos de datos de manera eficiente.
Proporciona un mayor nivel de precisión en la predicción de resultados sobre el algoritmo del árbol de decisión.
Desventajas
Cuando se usa un bosque aleatorio, se requieren bastantes recursos para el cálculo.
Consume más tiempo en comparación con un algoritmo de árbol de decisiones.
No producen buenos resultados cuando los datos son muy escasos. En este caso, el subconjunto de características y la muestra de arranque producirán un espacio invariante. Esto conducirá a divisiones improductivas, que afectarán el resultado.
5.8.5 Bosques aleatorios para modelo de regresión
Para implementar este algoritmo en R utilizaremos la función rand_forest de la paquetería parsnip, esta función define un modelo que crea una gran cantidad de árboles de decisión, cada uno independiente de los demás. La predicción final utiliza todas las predicciones de los árboles individuales y las combina.
# Se declara el modelo de clasificación
library(ranger)
rforest_model <- rand_forest(
mode = "regression",
trees = 1000,
mtry = tune(),
min_n = tune()) %>%
set_engine("ranger", importance = "impurity")
# Se declara el flujo de trabajo
rforest_workflow <- workflow() %>%
add_model(rforest_model) %>%
add_recipe(receta_casas)
# Declaración del grid
rforest_param_grid <- grid_regular(
mtry(range = c(8,15)),
min_n(range = c(2,16)),
levels = c(13, 18)
)
ctrl_grid <- control_grid(save_pred = T, verbose = T)library(doParallel)
# Creación del cluster de trabajo
UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
# V fold cross validation
ames_folds <- vfold_cv(ames_train, v = 10)
# Ajuste de parámetros
rft1 <- Sys.time()
rforest_tune_result <- tune_grid(
rforest_workflow,
resamples = ames_folds,
grid = rforest_param_grid,
metrics = metric_set(rmse, rsq, mae),
control = ctrl_grid
)
rft2 <- Sys.time(); rft2 - rft1
# Se detiene el cluster
stopCluster(cluster)
# Se guardan los resultados en formato RDS
rforest_tune_result %>% saveRDS("models/random_forest_model_reg.rds")rforest_tune_result <- readRDS("models/random_forest_model_reg.rds")
# R cuadrada
rforest_tune_result %>% autoplot(metric = "rsq") +
xlab('Número mínimo de elementos por nodo')+
ylab('R cuadrada')+
ggtitle('Gráfica R cuadrada')+
guides(color = guide_legend(title = 'Número de ramas'))+
theme_minimal()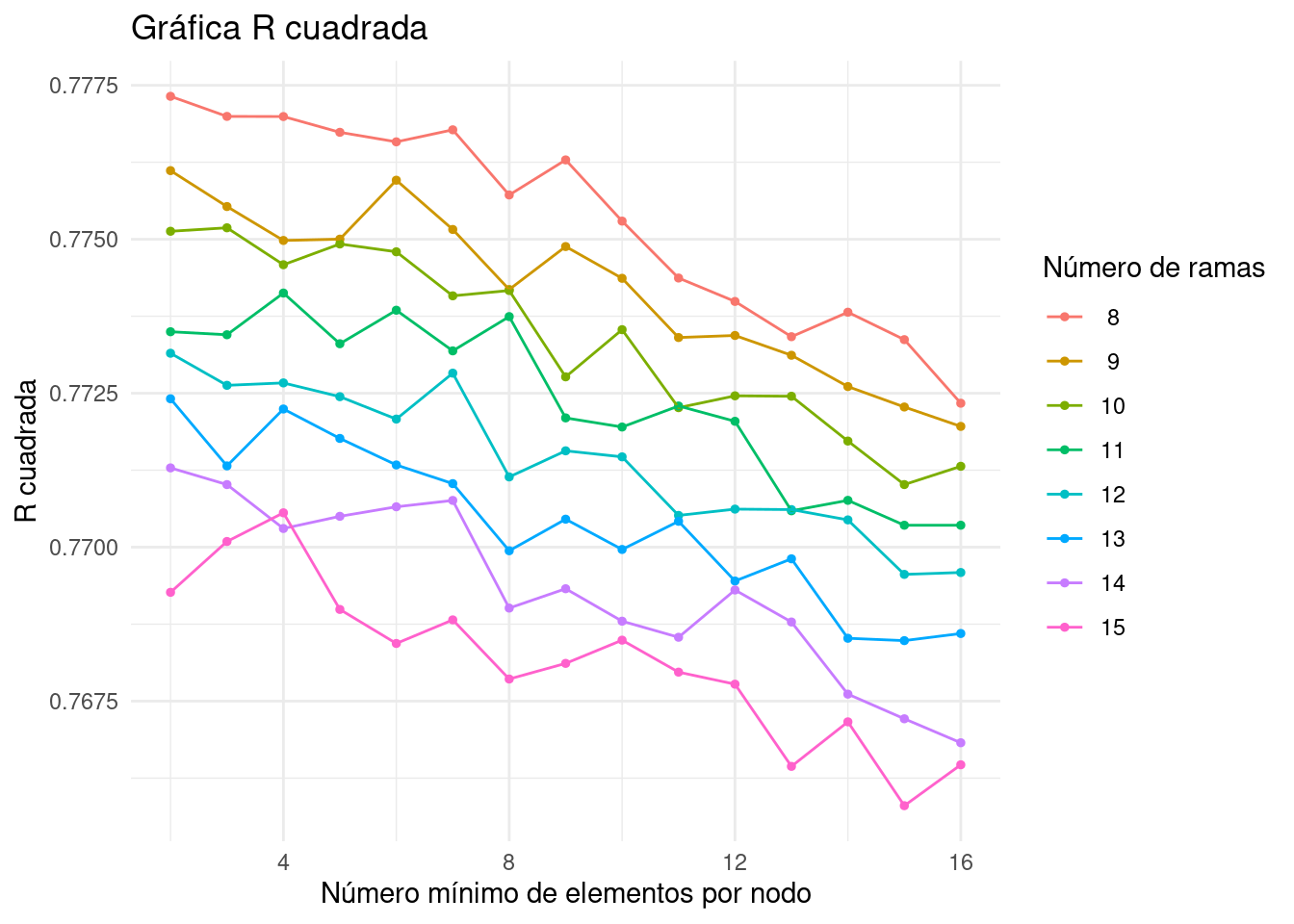
# Resumen de métricas
rforest_tune_result %>%
collect_metrics() %>%
group_by(.metric) %>%
summarise(
mean_max = max(mean),
mean_min = min(mean),
mean_mean = mean(mean),
mean_median = median(mean),
.groups = "drop"
)## # A tibble: 3 × 5
## .metric mean_max mean_min mean_mean mean_median
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 mae 180543. 180543. 180543. 180543.
## 2 rmse 197194. 197194. 197194. 197194.
## 3 rsq 0.777 0.766 0.772 0.772# Mejores 10 resultados
show_best(rforest_tune_result, n = 10, metric = "rsq") %>%
as.data.frame()## mtry min_n .metric .estimator mean n std_err .config
## 1 8 2 rsq standard 0.7773207 10 0.01428446 Preprocessor1_Model001
## 2 8 3 rsq standard 0.7769947 10 0.01416865 Preprocessor1_Model009
## 3 8 4 rsq standard 0.7769923 10 0.01438773 Preprocessor1_Model017
## 4 8 7 rsq standard 0.7767768 10 0.01426232 Preprocessor1_Model041
## 5 8 5 rsq standard 0.7767364 10 0.01448987 Preprocessor1_Model025
## 6 8 6 rsq standard 0.7765816 10 0.01450118 Preprocessor1_Model033
## 7 8 9 rsq standard 0.7762883 10 0.01439961 Preprocessor1_Model057
## 8 9 2 rsq standard 0.7761141 10 0.01466429 Preprocessor1_Model002
## 9 9 6 rsq standard 0.7759585 10 0.01439145 Preprocessor1_Model034
## 10 8 8 rsq standard 0.7757190 10 0.01460913 Preprocessor1_Model049# Selección del mejor modelo según la métrica r cuadrada
best_rforest_model <- select_best(rforest_tune_result, metric = "rsq")
# Selección del mejor modelo por un error estándar
best_rforest_model_1se <- select_by_one_std_err(
rforest_tune_result, metric = "rsq", "rsq")
# Selección del mejor modelo
final_rforest_model <- rforest_workflow %>%
#finalize_workflow(best_rforest_model) %>%
finalize_workflow(best_rforest_model_1se) %>%
fit(data = ames_train)# Predicciones
results <- predict(final_rforest_model, ames_test) %>%
dplyr::bind_cols(truth = ames_test$Sale_Price) %>%
dplyr::rename(pred_rforest_model = .pred, Sale_Price = truth)
head(results, 10)## # A tibble: 10 × 2
## pred_rforest_model Sale_Price
## <dbl> <int>
## 1 11.8 105000
## 2 12.1 185000
## 3 12.1 180400
## 4 11.5 141000
## 5 12.2 210000
## 6 12.2 216000
## 7 12.0 149900
## 8 11.6 105500
## 9 11.6 88000
## 10 11.9 1460005.8.6 Bosques aleatorios para modelo de clasificación
# Se declara el modelo de clasificación
rforest_model <- rand_forest(
mode = "classification",
trees = 1000,
mtry = tune(),
min_n = tune()) %>%
set_engine("ranger", importance = "impurity")
# Se declara el flujo de trabajo
rforest_workflow <- workflow() %>%
add_model(rforest_model) %>%
add_recipe(telco_rec)
# Declaración del grid
rforest_param_grid <- grid_regular(
mtry(range = c(8,15)),
min_n(range = c(2,16)),
levels = c(6, 8)
)
ctrl_grid <- control_grid(save_pred = T, verbose = T)library(doParallel)
library(ranger)
# Creación del cluster de trabajo
UseCores <- detectCores() - 1
cluster <- makeCluster(UseCores)
registerDoParallel(cluster)
# Ajuste de parámetros
rft1 <- Sys.time()
rforest_tune_result <- tune_grid(
rforest_workflow,
resamples = telco_folds,
grid = rforest_param_grid,
metrics = metric_set(roc_auc, pr_auc, sens),
control = ctrl_grid
)
rft2 <- Sys.time(); rft2 - rft1
# Se detiene el cluster
stopCluster(cluster)
# Se guardan los resultados en formato RDS
rforest_tune_result %>% saveRDS("models/random_forest_model.rds")rforest_tune_result <- readRDS("models/random_forest_model.rds")
# Curva de precisión
rforest_tune_result %>%
unnest(.metrics) %>%
filter(.metric == "pr_auc") %>%
ggplot(aes(x = mtry, y = .estimate)) +
scale_x_log10() +
geom_line(aes(color = id))+
ggtitle('Gráfica de precisión') +
theme_minimal()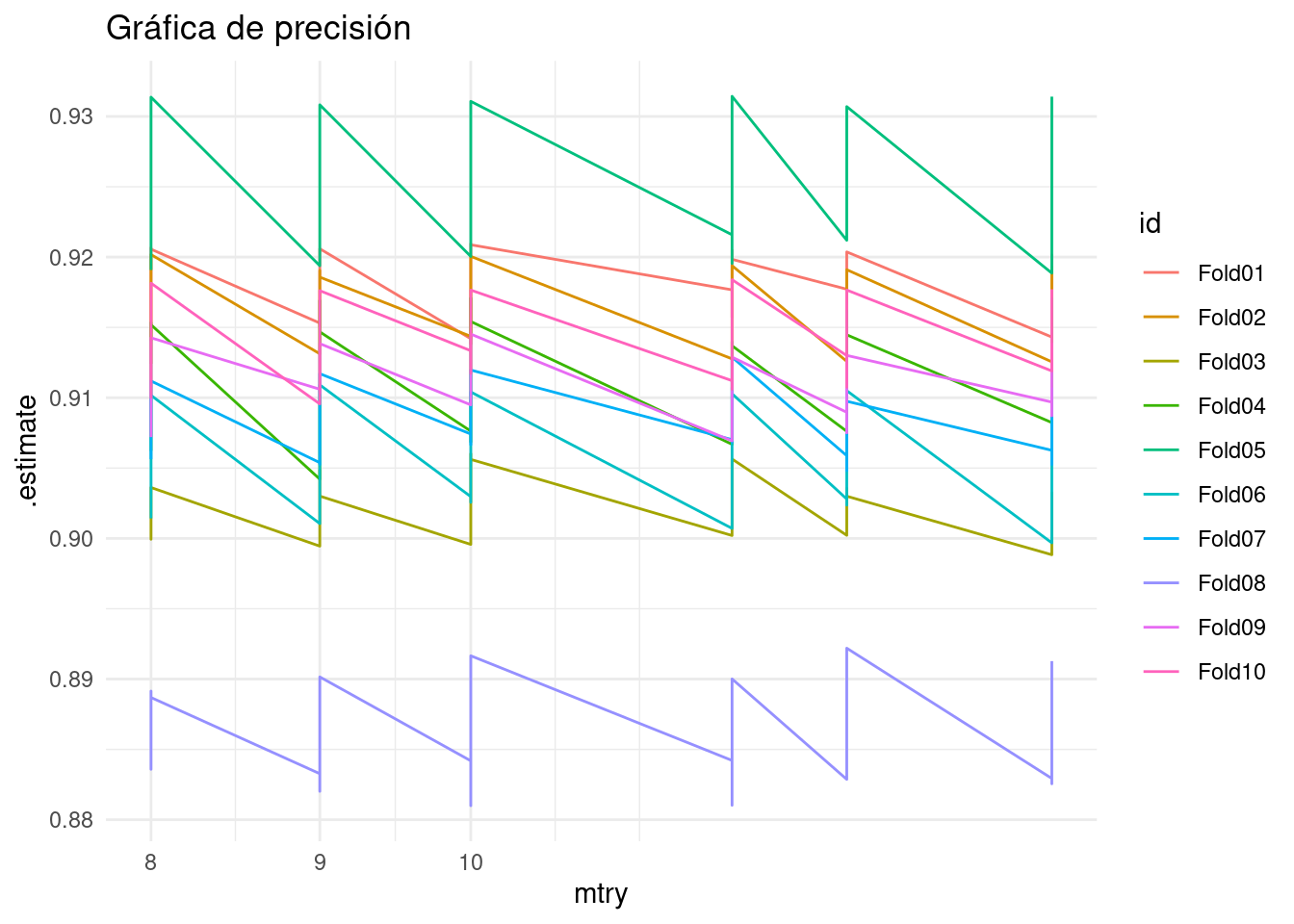
rforest_tune_result %>% autoplot(metric = "pr_auc") +
xlab('Número mínimo de elementos por nodo')+
ylab('Precisión')+
ggtitle('Gráfica de precisión por tamaño de nodos')+
guides(color = guide_legend(title = 'Número de ramas'))+
theme_minimal()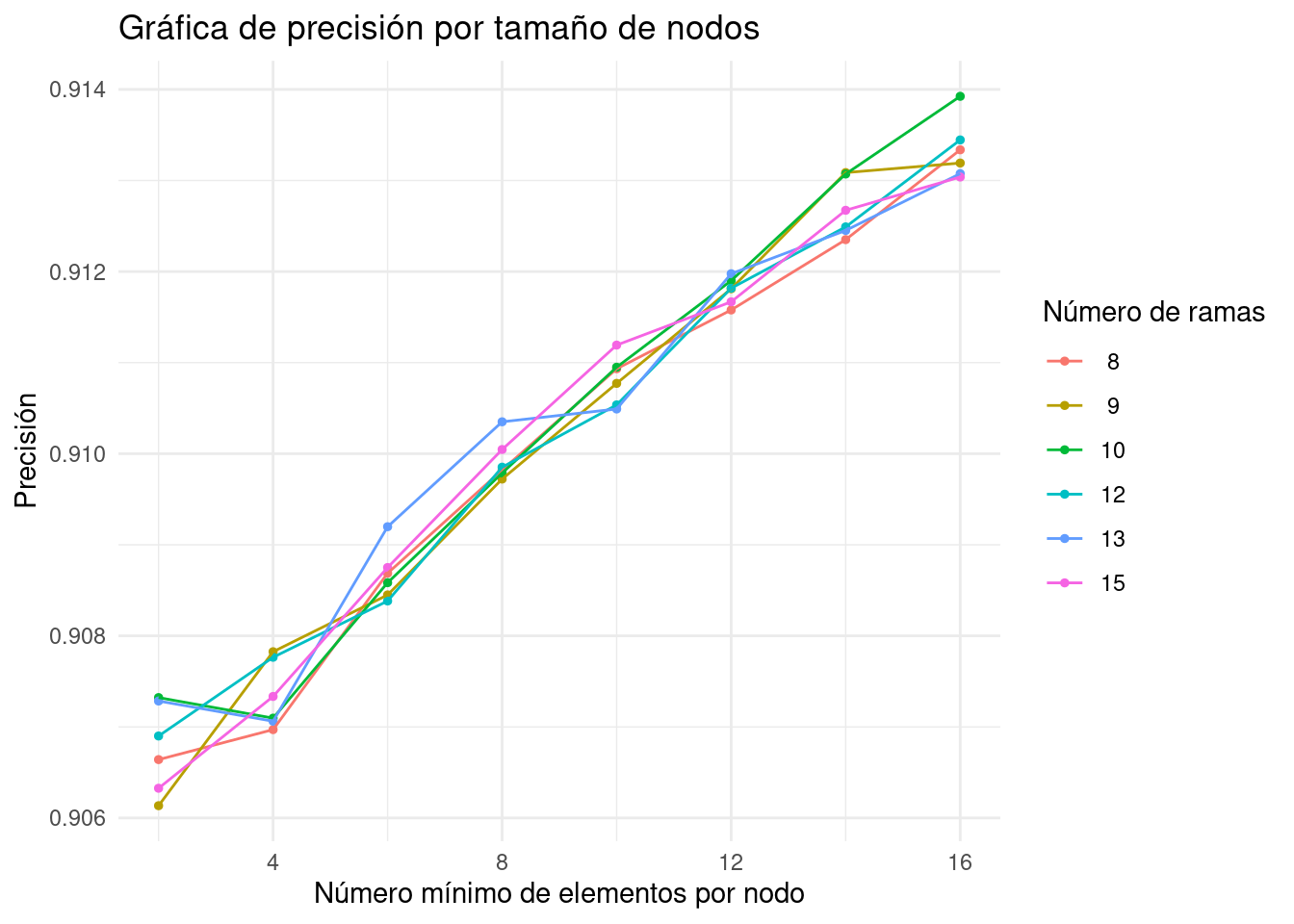
# Resumen de métricas
rforest_tune_result %>%
collect_metrics() %>%
group_by(.metric) %>%
summarise(
mean_max = max(mean),
mean_min = min(mean),
mean_mean = mean(mean),
mean_median = median(mean),
.groups = "drop"
)## # A tibble: 3 × 5
## .metric mean_max mean_min mean_mean mean_median
## <chr> <dbl> <dbl> <dbl> <dbl>
## 1 pr_auc 0.914 0.906 0.910 0.910
## 2 roc_auc 0.798 0.781 0.790 0.790
## 3 sens 0.893 0.871 0.883 0.884# Mejores 20 resultados
show_best(rforest_tune_result, n = 20, metric = "pr_auc") ## # A tibble: 20 × 8
## mtry min_n .metric .estimator mean n std_err .config
## <int> <int> <chr> <chr> <dbl> <int> <dbl> <chr>
## 1 10 16 pr_auc binary 0.914 10 0.00330 Preprocessor1_Model45
## 2 12 16 pr_auc binary 0.913 10 0.00341 Preprocessor1_Model46
## 3 8 16 pr_auc binary 0.913 10 0.00360 Preprocessor1_Model43
## 4 9 16 pr_auc binary 0.913 10 0.00343 Preprocessor1_Model44
## 5 9 14 pr_auc binary 0.913 10 0.00340 Preprocessor1_Model38
## 6 13 16 pr_auc binary 0.913 10 0.00330 Preprocessor1_Model47
## 7 10 14 pr_auc binary 0.913 10 0.00338 Preprocessor1_Model39
## 8 15 16 pr_auc binary 0.913 10 0.00341 Preprocessor1_Model48
## 9 15 14 pr_auc binary 0.913 10 0.00337 Preprocessor1_Model42
## 10 12 14 pr_auc binary 0.912 10 0.00341 Preprocessor1_Model40
## 11 13 14 pr_auc binary 0.912 10 0.00332 Preprocessor1_Model41
## 12 8 14 pr_auc binary 0.912 10 0.00346 Preprocessor1_Model37
## 13 13 12 pr_auc binary 0.912 10 0.00338 Preprocessor1_Model35
## 14 10 12 pr_auc binary 0.912 10 0.00329 Preprocessor1_Model33
## 15 12 12 pr_auc binary 0.912 10 0.00324 Preprocessor1_Model34
## 16 9 12 pr_auc binary 0.912 10 0.00332 Preprocessor1_Model32
## 17 15 12 pr_auc binary 0.912 10 0.00336 Preprocessor1_Model36
## 18 8 12 pr_auc binary 0.912 10 0.00347 Preprocessor1_Model31
## 19 15 10 pr_auc binary 0.911 10 0.00340 Preprocessor1_Model30
## 20 10 10 pr_auc binary 0.911 10 0.00346 Preprocessor1_Model27# Selección del mejor modelo según la métrica de precisión
best_rforest_model <- select_best(rforest_tune_result, metric = "pr_auc")
# Selección del mejor modelo por un error estándar
best_rforest_model_1se <- select_by_one_std_err(
rforest_tune_result, metric = "pr_auc", "pr_auc")
# Selección del mejor modelo
final_rforest_model <- rforest_workflow %>%
finalize_workflow(best_rforest_model_1se) %>%
fit(data = telco_train)## Warning: 8 columns were requested but there were 3 predictors in the data. 3
## will be used.# Predicciones
results_rforest_clas <- predict(final_rforest_model, telco_test, type = 'prob') %>%
dplyr::bind_cols(truth =telco_test$Churn) %>%
mutate(truth = factor(truth, levels = c('No', 'Yes'), labels = c('No', 'Yes')))
head(results_rforest_clas, 10)## # A tibble: 10 × 3
## .pred_No .pred_Yes truth
## <dbl> <dbl> <fct>
## 1 0.943 0.0566 No
## 2 0.199 0.801 Yes
## 3 0.589 0.411 No
## 4 0.989 0.0107 No
## 5 0.970 0.0303 No
## 6 0.407 0.593 No
## 7 0.990 0.0102 No
## 8 0.774 0.226 No
## 9 0.484 0.516 Yes
## 10 1.00 0.000393 Noresults_cla_rforest <-results_rforest_clas# Curvas pecision recall y ROC
pr_curve_rforest_clas <- pr_curve(results_rforest_clas, truth = truth, estimate = .pred_Yes, event_level = 'second')
roc_curve_rforest_clas <- roc_curve(results_rforest_clas, truth = truth, estimate = .pred_Yes, event_level = 'second')library(patchwork)
pr_curve_plot <- pr_curve_rforest_clas %>%
ggplot(aes(x = recall, y = precision)) +
geom_path(size = 1, colour = 'lightblue') +
coord_equal() +
ggtitle("Precision vs Recall")+
theme_minimal()
roc_curve_plot <- roc_curve_rforest_clas %>%
ggplot(aes(x = 1 - specificity, y = sensitivity)) +
geom_path(size = 1, colour = 'lightblue') +
geom_abline() +
coord_equal() +
ggtitle("ROC Curve")+
theme_minimal()
pr_curve_plot + roc_curve_plot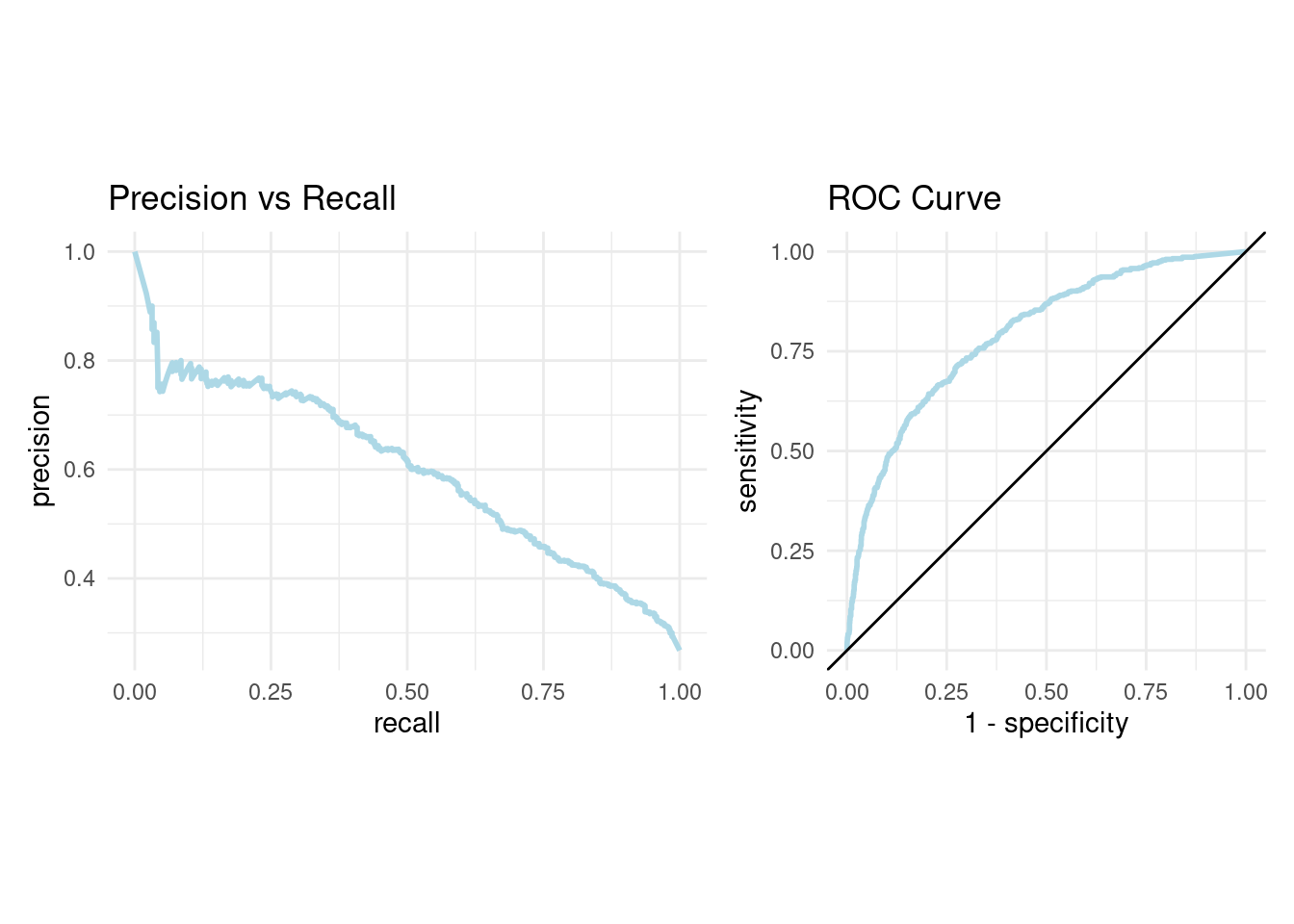
5.8.7 Importancia de las variables
Después de entrenar un modelo, es natural preguntarse qué variables tienen el mayor poder predictivo. Las variables de gran importancia son impulsoras del resultado y sus valores tienen un impacto significativo en los valores del resultado. Por el contrario, las variables con poca importancia pueden omitirse de un modelo, lo que lo hace más simple y rápido de ajustar y predecir.
library(vip)
final_rforest_model %>%
pull_workflow_fit() %>%
vip::vip() +
ggtitle("Importancia de las variables")+
theme_minimal()## Warning: `pull_workflow_fit()` was deprecated in workflows 0.2.3.
## Please use `extract_fit_parsnip()` instead.
Existen dos medidas de importancia para cada variable en el bosque aleatorio:
- La primera medida se basa en cuánto disminuye la precisión cuando se excluye la variable.
Primero, se mide la precisión de la predicción en la muestra fuera de la bolsa. Luego, los valores de la variable en la muestra fuera de la bolsa se mezclan aleatoriamente, manteniendo todas las demás variables iguales. Finalmente, se mide la disminución en la precisión de la predicción en los datos mezclados.
Se reporta la disminución media de la precisión en todos los árboles.
- La segunda medida se basa en la disminución de la impureza de Gini cuando se elige una variable para dividir un nodo.
Cuando se construye un árbol, la decisión sobre qué variable dividir en cada nodo utiliza un cálculo de la impureza de Gini.
Para cada variable, la suma de la disminución de Gini en cada árbol del bosque se acumula cada vez que se elige esa variable para dividir un nodo. La suma se divide entre la cantidad de árboles en el bosque para obtener un promedio. La escala es irrelevante: solo importan los valores relativos.
Ve este artículo para más información sobre la impureza de Gini.
5.9 Comparación de modelos
Comparemos las curvas ROC y Precision-Recall de los modelos de clasificación que hemos creado
# Curvas pecision recall y ROC
pr_curve_plot <- results_pr_curve %>%
ggplot(aes(x = recall, y = precision, color = ID)) +
geom_path(size = 1) +
coord_equal() +
ggtitle("Precision vs Recall")+
theme_minimal()
roc_curve_plot <- results_roc_curve %>%
ggplot(aes(x = 1 - specificity, y = sensitivity, color = ID)) +
geom_path(size = 1) +
geom_abline() +
coord_equal() +
ggtitle("ROC Curve")+
theme_minimal()
pr_curve_plot 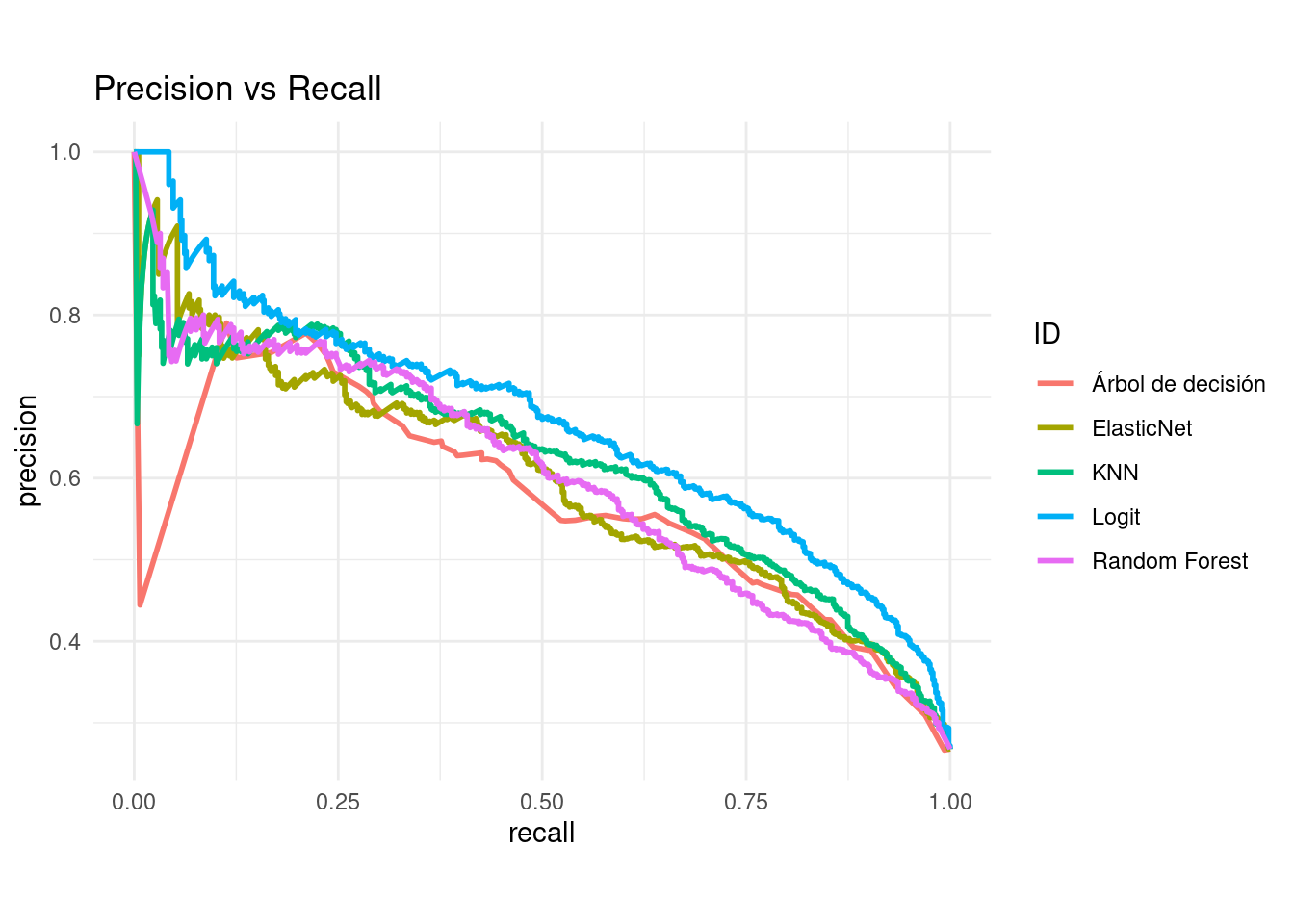
roc_curve_plot